Abstract
This study uses the motion semantic grid (Ibarretxe-Antuñano, 2019) to analyze the semantics of literary Chinese ideophones that depict motion (N = 313). I offer strategies for handling missing values in the Grid and enhancements specific to Chinese data, such as the inclusion of semantic radicals. Utilizing multiple correspondence analysis (mca), I identify the most salient elements and distances between items. The findings reveal that (1) all first-level components in the Grid play a role, e.g. figure, ground, motion, path, manner, cause, event extension; (2) of second-level components Animacy, Quanta, Basic level, Motor-pattern, Semantic radical, Motion, Direction, and Aspect contribute most to the first three latent dimensions; (3) motion ideophones cluster in salient groups. This study confirms the motion semantic grid’s utility for studying motion ideophones but highlights the need for language-specific adaptations and strategies for handling missing values absent from the original proposal.
1 Introduction
Motion events have been well-studied in Mandarin Chinese, with proposals ranging from satellite-framed classification (Talmy, 2000a) to equipollently-framed categorization (Slobin, 2004) to Macro-Event Hypothesis treatment (Li, 2018) and the similar cognitive-functional approach (Lin, 2019). The three approaches are illustrated in (1–3). There is increasing attention for the different morphemes that create a holistic motion event. These morphemes that participate in Chinese motion events consist of a relatively small set of closed-class path verbs that can combine with a large open class of manner verbs, ranging from generic to specific.
Despite the considerable attention to Chinese motion events, ideophones have hardly played a role in it. This is surprising on two accounts. First, Chinese has a sizeable iconic lexicon filled with items that depict [manner] or [manner + path], e.g. pánghuáng 徬徨 ‘walk back and forth’, zhǎnzhuǎn 輾轉 ‘toss and turn (in bed)’, gǔngǔn 滾滾 ‘rolling, surging’. An apparent explanation is that these items belong to a stratum of literary ideophones which tend to be used in written language (Van Hoey, 2018) and rarely figure as the clausal nucleus in contemporary Mandarin Chinese. In colloquial usage, we are more likely to encounter sound depictions (Thompson, 2018) that contribute to a holistic motion event, as has also been noticed for Pastaza Quechua (Nuckolls, 2014). Alternatively, they appear at the clause edge, which is not unusual from a typological point of view (Dingemanse & Akita, 2017).
Second, ideophones have played a role in the formation of motion-related typological theory. Slobin’s (2004) challenge to the Talmyan framework in which he posits a third type (equipollently-framed languages) next to verb-framed and satellite-framed languages rests not only on serial verbs (as in the case of Thai and Chinese, see example 3) but also on ideophonic items (4) that resist simple and easy classification into the Talmyan dichotomy. There is perhaps more room for this in the Macro-Event Hypothesis account (Li, 2018) but as of yet they have not been integrated.
Furthermore, it has been argued that motion events in Chinese have evolved from verb-framed to satellite-framed (or equipollently-framed). Shi & Wu (2014) show that the classification of Chinese motion events throughout time is not clear-cut but a mixed bag with statistical preferences per time period. But again, ideophones are not considered in this study, despite their usage throughout time. This may be due to their depictive semantics and usage, which run parallel to more well-studied prosaic grammatical structures. Still, to ignore this class of words that also clearly depict motion events is unfortunate, as they are present across many different genres, including poetry (see 5) and prose, but in fact also contemporary songs (see 6) or social media. In other words, while these are literary Chinese ideophones, people are still confronted with them through education (example 5 comes from a poem that is canon) or popular culture (Jay Chou in example 6 is one of the most popular singers). On the other hand, it should be noted that not all examples given in this paper have stood the test of time and will be familiar to speakers of Modern Chinese. But as a group of words that display similar characteristics, familiarity to the modern speaker is not a criterion for excluding words that never appear in Modern (Mandarin) Chinese.
Subsequently, one can wonder (a) how these literary Chinese motion ideophones as a category are internally structured, and (b) how their internal configuration compares to inventories of motion ideophones from other languages. In this study, the first of these two questions is addressed by using a cross-linguistic framework that allows future research to address the second question. Topically, the data consist of Chinese ideophones which express motion, appear in the Chinese Ideophone Database (Van Hoey & Thompson, 2020), and which belong to the literary Chinese stratum. As illustrated by the examples mentioned thus far, this stratum contains items that are rich in motion-related semantics, making them an ideal candidate to investigate the structure. Methodologically, the study makes use of an etic framework for cross-linguistic comparison, namely the motion semantic grid (Ibarretxe-Antuñano, 2019). In Section 2, this grid is introduced. Section 3 details the materials used, the statistical methodology (Multiple Correspondence Analysis) for quantitatively extending the motion semantic grid, and the annotation process to prepare data for the statistics (Section 3.3). In the latter section three recommendations are made for applying the motion semantic grid to linguistic data, as well as a number of adaptations that appear necessary for the current data set. In Section 4, the results of the Multiple Correspondence Analysis are presented, starting from first- and second-level components of the motion semantic grid, followed by third-level components, and finally by inspecting how the actual items appear in the Multiple Correspondence Analysis. This is followed by the conclusion.
2 The Motion Semantic Grid
It is well-known that motion occupies a central position in the work of Talmy (2000a, 2000b), which is aimed at identifying crucial cognitive concepts for describing the interplay between language and cognition. With regards to ideophones, there is ample work that explores how ideophones can be integrated in a typology that focuses on motion. For example, ideophones played an important role in fundamental critiques of Talmy’s verb-framed and satellite-framed verb typology (Slobin, 2004). Such critiques were based in part on observations by Ibarretxe-Antuñano about motion events in Basque narratives (Ibarretxe-Antuñano, 2004). Fifteen years later, she synthesized subsequent work and thinking about ideophonic motion events (e.g., Akita, 2012; Toratani, 2012; Nuckolls, 2014) into a “first attempt to provide the necessary tools to build up a semantic typological classification for motion ideophones” (Ibarretxe-Antuñano, 2019: 146), namely the motion semantic grid.
The motion semantic grid has the ambitious task to provide an etic grid for analyzing relevant aspects of motion ideophones. Ideophones that can be included must meet two criteria. Criterion 1: they are drawn from attested reliable sources, such as dictionaries, research articles, and books. In other words, they cannot be ad hoc vocalizations but must meet a certain threshold of entrenchment and conventionalization. Criterion 2: their first or only meaning must be in the semantic domain of motion (Ibarretxe-Antuñano, 2019: 147).
Key for the analysis is that it looks at salient aspects of such motion ideophones at three different levels of granularity: First-level semantic components (capital letters), second-level components (First letter capitalized), and third-level subcomponents ({squiggly brackets in running text}). There are 7 first-level semantic components: (1) figure, (2) ground, (3) cause, (4) motion, (5) event extension, (6) path, and (7) manner. According to Talmy (2000a: 25–29) a Motion Event consists of one object (figure) that moves or is situated (motion) with respect to another object (ground) along a certain trajectory (the path). Additionally, the way in which this motion happens can be highlighted (manner), or the force that enables the motion to happen (cause). Later, aspect (event extension) is also identified as a fundamental notion in the Motion Event (Talmy, 2000a: 67–69; see also Toratani, 2024).
Beyond these seven, the motion semantic grid is characterized as non-exhaustive and open-ended (Ibarretxe-Antuñano, 2019: 147), entailing that number counts for the levels of second-level and third-level subcomponents is dynamic, as long as those levels add new crucial information or miss out on pervasive characteristics across several ideophones. Ibarretxe-Antuñano thus subtly expresses the expectation that modifications to the grid will only involve additions, but as we will see below, that may not necessarily be the case.
As an illustration, we present three items from Appendix 2 in Ibarretxe-Antuñano (2019): Upper Nexaca Totonac liŋʃiliŋʃi ‘a heavy animal walking and making the ground shake’, and Semai parparpar1 ‘noise of appearance of birds in flight’, and parparpar2 ‘noise of fish struggling among roots in water’. The latter is interesting because there are two definitions associated with it, one pertaining to bird, the other two fish. The motion semantic grid handles this by splitting them and annotating the grid for both semantic construals. Thus, parparpar1 means ‘noise of appearance of birds in flight’, and parparpar2 means ‘noise of fish struggling among roots in water’. The annotated grid is provided in Table 1.
What immediately stands out in Table 1 is the number of missing values in the table. This is a design feature of the motion semantic grid that allows quick calculation of those (sub)components that are salient for motion ideophone inventories of particular languages. For example, based on the illustrative data (N = 2) here, one would infer that the Semai motion ideophonic inventory has at least salient elements for figure, ground, cause, motion, event extension, and manner, but not necessarily path, at the first-level of analysis. On the second level, it would have Quanta (figure), Animacy (figure), Type (ground), Causer (cause), Moving (motion), Phase (event extension), Motor Pattern (manner), Force (manner), Casualness (manner), and Sound (manner). The third level, then, involves the actual levels that the second level takes. For example, Motor Pattern (manner) has the third-level components of {walk, fly, swim} here.
In Ibarretxe-Antuñano’s (2019) such calculations are largely used to investigate which aspects of motion tend to be saliently expressed across languages. In other words, the motion semantic grid acts as a typological tool. The conclusion of that introductory chapter is that motion semantics of ideophones is challenging, due to ideophones containing a number of cross-linguistic tendencies that are mediated by language-particular peculiarities. It ends with a call for more full motion ideophone inventories need to be described, in order to further investigate the potential of using the motion semantic grid as a tool for generalization based on statistically valid methods. In the remainder of this study, this call is heeded, through the application of the motion semantic grid to Chinese literary ideophones that express motion. In the subsequent sections, it will be shown that the architecture of the motion semantic grid on the whole is useful but can be more effective with a number of changes.
3 Materials and Methods2
3.1 Materials
As outlined in the introduction, Chinese has an iconic inventory that consists of different strata of ideophone or ideophone-like elements: typical onomatopoeias, literary ideophones, and collocate-ideophone compounds. Examples of typical onomatopoeias (Mueller-Liu, 2017; Thompson, 2018; Van Hoey, 2024) include gūgū 咕咕 ‘cooing (pigeon)’, kuāngchī kuāngchī 哐哧哐哧 ‘wheels of a train’, wēngwēng 嗡嗡 ‘buzz (mosquito, fly)’. There is a layer of literary ideophones (Sun, 1999; Li, 2013; Van Hoey, 2018), e.g., línlí 淋漓 ‘dripping wet’, fēifēi 霏霏 ‘heavy rain, snow’, mángmáng 茫茫 ‘vast, boundless, indistinct’. Additionally, there is a group of semi-fixed collocate-ideophone compounds known as abb words (Cao, 1995; Van Hoey, 2023b; Van Hoey et al., 2024), e.g., xiōng-bābā 兇巴巴 ‘tough, grumpy’, lǜ-yóuyóu 綠油油 ‘lush and glossy green’, xiāng-pēnpēn 香噴噴 ‘very fragrant’.
Here, we restrict attention to literary ideophones that express motion, precisely because colloquial ideophones tend to primarily involve sound depictions (onomatopoeia), which interferes with Criterion 2 of including items whose primary meaning is about motion (see Section 2). abb words are also excluded, since there currently do not exist modal exclusivity ratings of these words, and the proportion of such items depicting motion cannot be adequately estimated. Literary ideophones, on the other hand, have been categorized according to major semantic domains, following Dingemanse (2012) and adaptions advanced later by McLean (2020) and Van Hoey (2023a). These domains include sound, motion, size, shape, color, texture, smell, taste, evaluation etc.
To follow Criterion 1 about entrenchment and conventionalization, the Chinese Ideophone Database (Van Hoey & Thompson, 2020) was queried for items that depict “motion” (N = 334), which were recorded in A student’s dictionary of Classical and Medieval Chinese (Kroll, 2015), and which are disyllabic, which is the most common type of ideophones in Chinese. The data were then manually subjected to Criterion 2 (primary definitions involving motion), resulting in N = 294 unique ideophone items. Similar to parparpar in Table 1, definitions were split when they involved completely different construals, increasing the total number of observations to N = 313. One caveat is that many of these words are not always immediately interpretable to native speakers of Mandarin, as informal discussions have shown. It is after all a dictionary-based survey. Some examples are shown in Table 2.
3.2 Methodology
The methodological goal of this study is to apply the motion semantic grid to the inventory of literary Chinese motion ideophones. In particular, we are interested in identifying which second- and third-level components are salient, while operating under the assumption that all first-level components are present in the data. In other words, we are not so much interested in hypothesis testing, but want to explore the utility of the motion semantic grid and how items in Chinese relate to each other.
An ideal method for such an exploration is Multiple Correspondence Analysis (mca), a variation on Principal Component Analysis (pca) that uses categorical data rather than numerical data (Greenacre, 2006; Abdi & Williams, 2010). A clear and concise introduction to simple Correspondence Analysis (ca) in linguistics is offered in Glynn (2014). An application of Multiple Correspondence Analysis to linguistic data with R code is provided by Levshina (2015: 367 ff.). In essence, these methods are used to reduce the dimensionality of the data. A helpful analogy is if you were to investigate tea consumption: you may find that green tea is often consumed right after lunch without milk or lemon, while black tea tends to be consumed with lemon at any given time, and flavored tea with milk and sugar at breakfast (Husson, Lê & Pagès, 2017: 140). This analogy has the variables tea (levels: green, black, flavored), how one drinks it (levels: with milk, with lemon, with nothing), and sugar addition (levels: yes, no). Dimensionality reduction methods of this paradigm thus try to find underlying structures to the data, that allow us to see which categorical values co-occur. In our case, the dimensions to be reduced are provided by the second-level components of the motion semantic grid. The levels come from the third-level components. Additionally, we will be able to project the actual ideophones on the conceptual space through the coordinates of the different dimensions that are the result of the Multiple Correspondence Analysis.
There are, however, two challenges that need to be addressed before we can conduct the mca. The first and most important one involves missing values (na values), that are part of the design of the motion semantic grid, illustrated by Table 1. While beneficial for easy calculation of salience points across languages, as done by Ibarretxe-Antuñano (2019), most statistical methods have an aversity for missing values (Kwak & Kim, 2017). This problem is usually identified by inspecting data before running a model (or finding out when the software throws an error), and solved by either dropping the missing observations, or by imputing most likely values based on the other columns. The second challenge involves the number of levels that the algorithm will need to handle. Since mca under the hood works with a complete disjunctive table (or “Burt table”), having a large number of levels makes this indicator matrix explode. Paradoxically, the ability to handle more categorical levels is what makes this method so attractive for analyzing the motion, but you get better results if there are fewer levels (ideally binary levels per variable).
Bearing this in mind, we can present three recommendations.
Recommendation 1: provide a dataset that is as complete as possible. This can be achieved by stating explicitly, for example, {sound not salient} in the second-level component Sound (see Table 1). In Section 3.3, we go over how the levels of the motion semantic grid need to be adapted in order to adhere to this recommendation.
Recommendation 2: try to be economical with the third-level components (levels). Most statistical modeling works best with fewer levels in categorical variables. Ideally, this means binary options. However, the nature of motion description is challenging, precisely because so many levels per variable are allowed. Collapsing and refactoring levels that make up a small minority or are conceptually similar aids in running the statistical machinery. Section 3.3 holds the details for which variables and levels were collapsed in this manner.
Recommendation 3: drop or impute observations and variables so that the algorithm can be used. We will do both. Section 3.3 details which second-level components (variables) are dropped due to lack of data or relevance. For the remaining data set, however we apply a version of mca called regularized iterative mca (Josse et al., 2012) to impute missing observations, followed by the standard mca algorithm.
The actual implementation of these algorithms is carried out in R (R Core Team, 2024), making use of the libraries FactoMineR (Lê, Josse & Husson, 2008) and (Kassambara & Mundt, 2020) for the mca, and missMDA (Josse & Husson, 2016) for the imputation of missing values. Data, code, and package versions can be found in the osf link provided at the beginning of Section 3.1. Before we impute and conduct the mca, we need to discuss how the motion semantic grid is to be adapted to follow Recommendation 1 to 3.
3.3 Annotation
The actual annotation of ideophonic data is time consuming and challenging (de Schryver, 2009; Ibarretxe-Antuñano, 2019). Arguably, the most subjective component of the annotation stage involves reading the definition, imagining the depicted scene, and filling out the motion semantic grid. This is mitigated by overt elements in the definition. For example, the definition of fēnfēn 翂翂 ‘float and flutter, drift with the wind (of birds)’ tells us that this item’s figure is a bird, floating in the wind (ground). From this it can be inferred that the Animacy (figure) is {non-human}, the Motor pattern (manner) is {fly} in the air, i.e. the ground has as Type {gaseous}. These elements are covertly present. It should be pointed out that such elucidation forms a large part of the work of foundational cognitive linguists like Talmy (2000b, 2000a) or Langacker (1987, 1991). The subjective interpretation of the annotation work is thus best viewed in this vein.
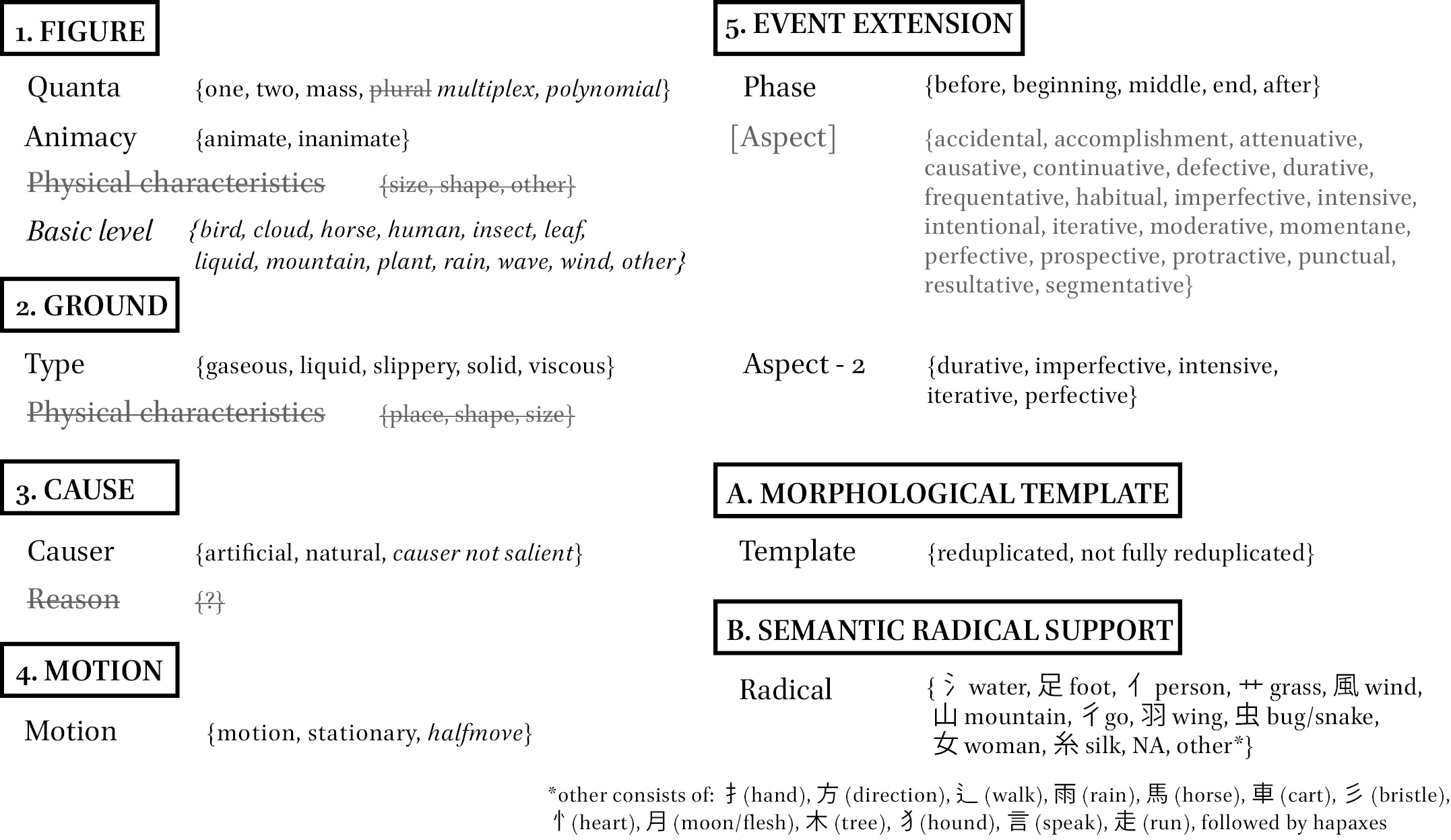
In the annotation, several choices need to be made about the three-level architecture of the motion semantic grid. First-level components (figure, ground, cause, motion, event extension, path, manner) were all found to be present. Due to the nature of Chinese data, however, we also add two other first-level components: morphological template and semantic radical support. First, we agree with Ibarretxe-Antuñano’s (2019: 151) statement that the inclusion of the morphological structure (levels for Basque: reduplication, singleton, derived) might reveal something about the semantic nature of ideophones (Baxter & Sagart, 1998: 95; Li & Ponsford, 2018). After all, diagrammatic iconicity is indeed a strong factor for ideophonehood (Dingemanse, 2012) and is part and parcel of iconic inventories across the world (Dingemanse & Akita, 2017; Akita & Dingemanse, 2019). Hence, we include morphological template with second-level component variable Template and third-level component levels {reduplicated, not fully reduplicated}, based on morphological statistics provided in the Chinese Ideophone Database (Van Hoey & Thompson, 2020).
Second, most Chinese characters consist of a semantic radical and a phonetic component. These semantic radicals often, and especially in the case of ideophones, reveal something about the broad category the meaning of the word is situated in (Chou & Huang, 2005; Hsieh, 2006; Van Hoey & Thompson, 2020). For example, fēifēi 霏霏 ‘heavy fall of snow or rain; flurried, pelting’ contains the semantic radical {⻗ rain} and phonetic component /fēi/ 非. When the same semantic radical appeared in both characters of the disyllabic items in the data, it was recorded as the level for the component semantic radical support (such radicals provide a semantic cue as to the meaning). This happens by default for full reduplications like fēifēi 霏霏, but is common as well for many partial reduplications, e.g., xiōngyǒng 洶湧 ‘waves crashing and curling, bubble and boil, swell and billow’. In this ideophone, the semantic radical {氵 water} can be observed. It need not be the case that semantic radical support is present, e.g. línglì 凌歷 ‘traverse and transit’ clearly depicts motion, but does not have semantic radical support. Summarizing, semantic radical support as a first-level component has as its second-level variable Radical, with third-level levels {氵 water, 足 foot, 亻 person, …}. They are shown in Figure 1.

Revised motion semantic grid (part 1). First-level components are given in all caps (e.g. figure), second-level variables with first letter capitalized (e.g. Quanta), third-level levels in roman surrounded by curly brackets (e.g. {one, two}). Strikethroughs indicate variables that were dropped due to irrelevance; square brackets indicate variables that were dropped because of data sparsity. Italics are used for novel variables and levels that are added to the motion semantic grid.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
Most other changes to the architecture of the motion semantic grid involve dropping second-level variables, such as Physical characteristics (for figure and ground), Phase (event extension) and Reason (cause). The first two turned out to be largely irrelevant for this particular dataset; the third one is not clearly illustrated in Ibarretxe-Antuñano (2019), making it hard to apply them to the current data. Examples of these are struck through in Figure 1 and Figure 2. There are also second-level variables that are omitted to meet the recommendations mentioned above. For instance, Aspect (event extension) has many similar levels, e.g., {iterative} (same event repeated) and {protractive} (same event on and on). Rather than arguing that the nuance between these two values is unimportant or insignificant, for the sake of modeling convergence these two should be collapsed. To address such collapsing issues in Aspect, a simplified variable called Aspect 2 is introduced with the following levels: {durative, imperfective, intensive, iterative, perfective}. It should be noted that there currently is no single unifying theory of ideophone aspect, although there are of course language-particular treatments (see Nuckolls (1996) for Pastaza Quechua; Toratani (2024) for Japanese). It is an open question how well the extensive list of the motion semantic grid’s original variable Aspect dovetails with other general treatments such as Vendler (1957) or Croft (2012), without losing particularities known from the reduplication literature (Li & Ponsford, 2018).
Revised motion semantic grid (part 2). First-level components are given in all caps (e.g. figure), second-level variables with first letter capitalized (e.g. Quanta), third-level levels in roman surrounded by curly brackets (e.g. {one, two}). Strikethroughs indicate variables that were dropped due to irrelevance; square brackets indicate variables that were dropped because of data sparsity. Italics are used for variables and levels that are added to the motion semantic grid
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
Other second-level variables that are omitted due to data sparsity (not reaching 60% coverage when filled out) are Figure-induced behavior, Step, Leg, and Instrument (manner), see Figure 2. While these are undoubtedly salient aspects of human motion, they are often not inferable during subjective construal. This is also related to the way in which the motion event is interpreted in this study, and which may not necessarily be the same for the other submissions to this special issue. In this case, we are dealing with boundary crossing events (Talmy walked into the room.) as well as non-boundary crossing events (Talmy walked for 10 minutes.). The latter is strictly speaking not what is meant with the term Talmyan motion event. However, motion in our rich ideophone data is interpreted at its broadest, including many inanimate forms of motion, such as rivers flowing or even rain or tears falling. Such figures in these events do not have steps, legs or instruments, and make up a sizeable portion of the data.
At the third-component level, a first modification was targeted at making missing values explicit. For instance, Quanta (figure) consists of {one, two, mass, plural} in the original version. We add to this list the value {polynomial} with the meaning “one or more”, for ideophones that are agnostic with regard to number of figures. The value {plural} is replaced with {multiplex} to fit more in with Talmy’s framework (Talmy, 2000a). We further reduce the original Animacy (figure) list of {inanimate, animate, human, child, old, non-human, no-legs, bipedal, quadrupedal, other} to just {animate, inanimate} and introduce a new second-level variable Basic level (figure) with values like {bird, cloud, horse, plant, …}. Animacy and Basic level together form a more economical way of representing the data that will be appreciated by the mca’s algorithm. There are few other third-level modifications that are represented with strikethroughs and italic in Figure 1 and Figure 2.
It must be stressed that the modifications here are mostly pertinent to these data, but we hope they are of use to future studies that wish to employ the motion semantic grid. By adapting the grid in this way, almost all variables can be filled out. Still, the regularized iterative mca method (Josse et al., 2012) is applied to the variable semantic radical support, so that the many levels of this variable do not disproportionally influence the analysis. The results of the multiple correspondence analysis are presented in Section 4.
4 Results
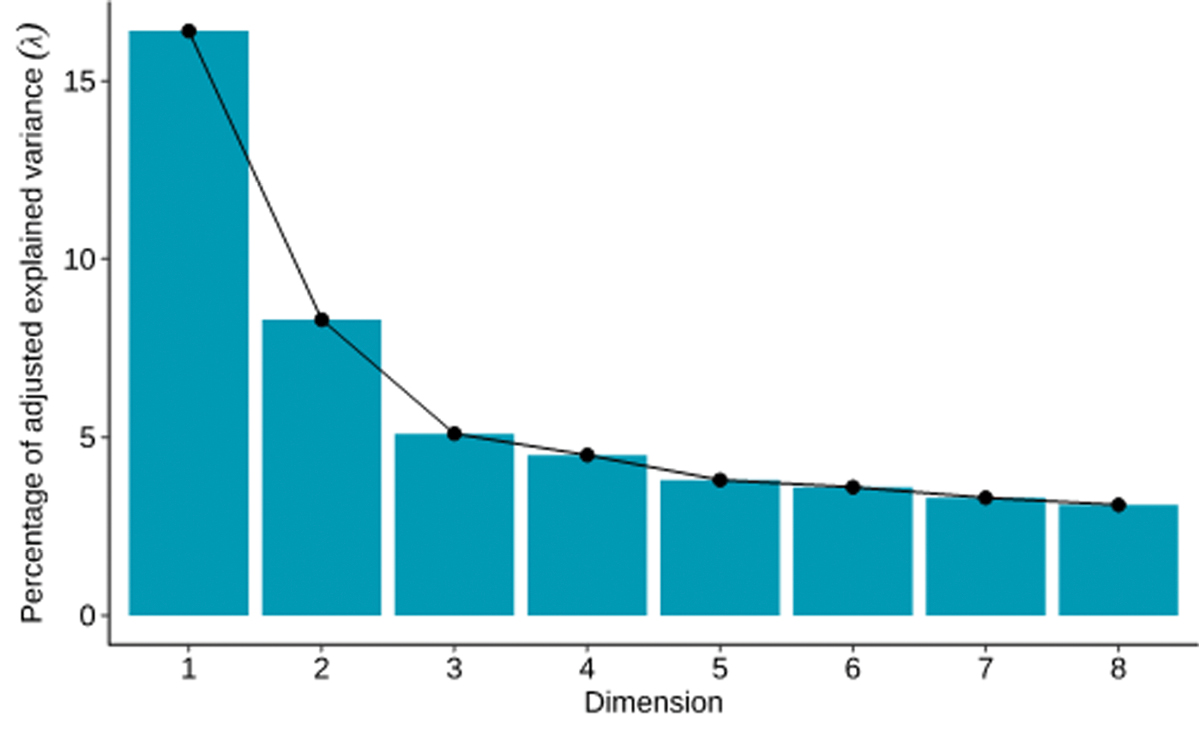
When conducting mca, it is customary to inspect the eigenvalues of the algorithm’s principal components (underlying dimensions) to decide how many should be considered in the interpretation. Together, these principal components account for a proportion of the variance in the data. With numerical Principal Component Analysis, these percentages are typically larger than categorical Multiple Correspondence Analysis. Greenacre (2006: 68) proposes reporting a scaled correction to these values that accounts for the large numbers of levels that are typically present in categorical data. The adjusted variance explained for the first three dimensions is as follows (Figure 3): dimension 1 accounts for 16.1 % (λ1 = 0.131529), dimension 2 for 8.1 % (λ2 = 0.066370) and dimension 3 for 5.0 % (λ3 = 0.041032). After these first dimensions, the contributions of subsequent dimensions decrease, as indicated by the elbow angle around dimension 3 in Figure 3. This indicates that two to three dimensions suffice for making inferences about the structure of the data.
Scree plot showing the adjusted explained variance in the Multiple Correspondence Analysis. The elbow angle around dimension 3 suggests that two to three dimensions suffice for further inspection, totaling to respectively 24.2 % and 29.2 % explained variance in the data.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
4.1 First- and Second-Level Components
Now that we established that two to three dimensions suffice for the mca analysis, it is possible to inspect to what degree the different second-level components (variables) of the motion semantic grid correlate with these three dimensions, which acts as a proxy for the importance of second-level components in the Chinese data. This can be quantified through the η2 (eta2) value of the different variables per dimension. For example, the visualization in Figure 4 shows that Direction (path) is correlated moderately well to all three dimensions:
Three-dimensional view of the η2 values of second-level components (e.g. aspect) per dimension. Second-level components are colored with regard to their respective first-level component.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
Figure 4 shows that not every second-level component is equally well represented in the first three dimensions of the Multiple Correspondence Analysis. Highly correlated with all three dimensions are Motor pattern and Basic level. That Motor pattern stands out is not surprising. After all, this is an analysis of motion ideophones following the motion semantic grid, and Motor pattern is arguably the most salient aspect of motion events. Basic level, the newly introduced second-level component for the first-level component figure, is equally salient in Figure 4, for similar reasons: you need to have an entity that moves in a motion description.
Other second-level components that are highly correlated with the first dimension are Quanta and Animate. Not surprisingly, these also have to do with aspects of figure. The difference with Basic level, however, is that they play a moderate role for dimension 2 and almost no role for dimension 3. Radical (semantic radical support) is important on dimension 1 and 2. For reasons that are specific to Chinese data, it is not surprising that this figures so high in these two dimensions. At the same time, the second-level component Radical is not generalizable to most other languages (most languages do not use a logographic writing system), showing that language-particular features do not always translate well. The aforementioned variables—Motor pattern, Basic level, Quanta, Animate, Radical—can be considered as the primary group of second-level components that play a salient role in our data set.
Looking at dimension 2 and 3, then, we see that Direction (path) is relatively important, indicating that while Motor Pattern (manner) was primary in the data, Chinese ideophones also have a salient path component. This observation dovetails well with the equipollently-framed proposal by Slobin (2004) but does not necessarily exclude other accounts that analyze Chinese motion events as being satellite-framed, since the data we take into account here comprise literary Chinese ideophones. These items would behave differently in Mandarin grammar. For example, it has been argued that motion events in Chinese have been evolving from a verb-framed type to a satellite-framed type (Shi & Wu, 2014), and literary Chinese ideophones appear to belong to the former type rather than the latter.
Other second-level components that are relevant for dimension 1 are Sound (figure) and Causer (cause); for dimension 2 they include Motion (motion), Rate (manner), Contour (path), and Aspect (event extension). Relevant for dimension 3 is Type (ground). We can call these the secondary group of second-level components. These are salient but not to the same extent as the primary group.
Finally, there exists a tertiary group of second-level components that contribute next to nothing to the first three dimensions, and which includes Template (morphological template), Casual (manner), Regularity (manner), Energy (manner) etc. It is entirely possible that these components score high on other dimensions beyond the first three, but their impact will be relatively minor in the structuring of the data set. This observation notwithstanding, it is still relevant to annotate these variables because other language data sets may contain different internal configurations of their motion ideophone vocabulary.
4.2 Third-Level Components
Zooming further in on the third-level components (i.e., the levels of the second-level components), we can see how they correlate with each other. Ideally, this is also presented in a three-dimensional plot like Figure 4, but the results were unclear on the printed page. For this reason, we present three snapshots of dimension combinations. Figure 5 shows the snapshot of dimension 1 and dimension 2, Figure 6 that of dimension 1 and dimension 3, and Figure 7 that of dimension 2 and dimension 3. To increase clarity, only the levels that contribute more than the expected contribution under the null hypothesis (here the cut-off point is 0.94) are included per figure. What makes mca plots so valuable is that we can use the geometric distance between items to interpret which levels co-occur in a data set. However, it should be borne in mind that the explained variance of dimension 1 is the highest. Hence, this should be the primary metric for the interpretation of these plots.
Third-level components plotted on dimension 1 and dimension 2.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
Third-level components plotted on dimension 1 and dimension 3. The third-level components of stationary and move (motion) can be disregarded, as they are plotted only for the consistent legend coloring.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
Third-level components plotted on dimension 1 and dimension 2.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
The bottom-left visualization in Figure 5 shows a clear water-related corner: literary Chinese ideophones that are {liquid, mass, wave, inanimate} (figure) tend to co-occur with some {sound and loud} Sounds (manner), but also have a {high} Energy (manner) and are {forceful} (manner). Not surprisingly, the semantic radical of {water 氵} turns up here. Turning to the bottom-right of Figure 5, we can see {animate and human} (figure) levels that tend to {walk} (manner) {erect}, in a {controlled, regular} manner. They can also {run} (manner) {along} (path) or in {zigzag} way (path). This section of Figure 5 tends to co-occur with the semantic radical of {person 亻} or {foot 足}. While the water section (bottom left) is characterized a mass Quanta (figure), the human movement section (bottom right) has Quanta values of {one} or {polynomial}, i.e., “at least one” (figure).
The bottom of Figure 5 captures levels that have to do with actual {movement} (motion). The top half of this figure, on the other hand, has to do with {stationary} (motion) levels. This is where Basic levels like {leaf, mountain, plant} (figure) are found. In terms of semantic radicals, we see this also in {mountain 山} and {silk 糸}. The Motor patterns (manner) associated with these levels are {hanging}, {winding and wrapping}, or simply {none}.
Compare these observations with Figure 6, which plots dimension 1 against dimension 3. This means that horizontally, we have the same values as in Figure 5, but the vertical dimension along the y-axis is completely different. This snapshot again captures a water section on the bottom left peninsula and a human movement on the bottom right peninsula. The mountain corner is flipped on the y-axis when compared against the previous plot. These low dimension 3 values of the {mountain} (figure) section are contrasted with a top half of the plot that contains Basic levels such as {bird, wind, leaf} (figure), which are characterized by Motor patterns like {blow, flutter, fly, oscillate} (manner). This first contrast stands out: while dimension 2 placed leaves and mountains together as a relatively {stationary} (motion) group, dimension 3 disentangles them, allowing for other salient clusters to appear: birds (characterized by the semantic radical of {wing 羽}) and items that experience the wind (semantic radical {wind 風}).
Let us now focus on the path expressions as shown in Figure 6. Water tends to follow a {criss-cross} path {toward} the figure of the event. Human motion tends to {go along} or follow a {zig-zagging} path. It is not inconceivable that mountains correlated with paths that express {curves} or {going around}. Wind and leaf are blown {through} or along a certain {contour}, while birds also follow a {contour} path (a certain trajectory) although they also often fly {back and forth}. Additionally, there is a clear trichotomy present in Figure 6, namely that of ground. {Liquid} grounds feature in the water section, {solid} grounds in the human and mountain sections and {gaseous} grounds in the bird and wind section.
Finally, Figure 7 contains dimension 2 against dimension 3. It is most useful to interpret this plot by investigating Aspect (event extension). The right-hand side is characterized by {imperfective} Motor patterns, e.g., {fly, oscillate, hang, winding, wrapping}, all in a slow and unrestrained manner. The left-hand side features {durative} and {perfective} actions, like {running, blowing, walking} etc. As mentioned before, the aspectual divisions have been simplified and deserve follow-up investigations. Beside this point, Figure 7 affirms what have been seen from dimension 2 and dimension 3 in the two preceding plots.
4.3 Motion Ideophones Clustered
The Multiple Correspondence Analysis (Section 4.2) has shown that the data are structured in different clusters with regard to the levels (third-level components) and variables (second-level components). We are now able to project the actual literary Chinese motion ideophones on top of these three dimensions. Note that these items themselves did not participate in the analysis, because they are so-called supplementary variables: we want to say something about them based on the properties of the different motion semantic grid variables.
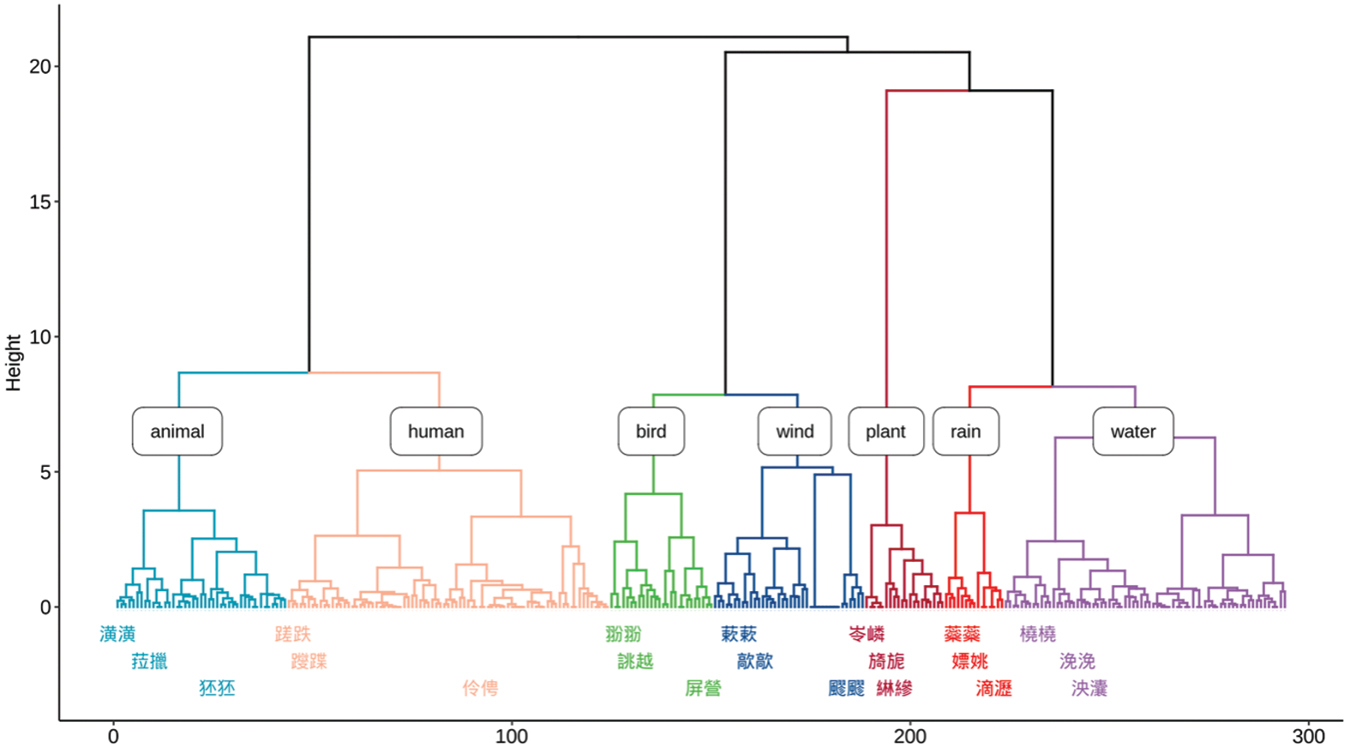
To further understand the clusters that exist within the data, we first run a hierarchical clustering algorithm (based on Ward’s criterion) over the first three dimensions of the mca analysis. This results in a dendrogram (Figure 8) from which we retain seven main clusters, as this is the level that corresponds most closely to the findings of the mca in Section 4.2. These clusters have been labeled following the Basic level items that the clusters were mostly composed of: animal, human, bird, wind, plant, rain, water. Of course, at different levels we can discern different groupings. For example, there is a major split between [animal, human] and [bird, wind, plant, rain, water], the latter of which can be divided in [bird, wind], [plant], [rain, water]. It is clear that such groupings follow a natural classification in terms of semantics, but also of course all the other variables that have a high impact on the first three dimensions of the mca, see Section 4.1.
Dendrogram (Ward’s criterion) based on the first three dimensions of the mca analysis. Interpretative labels have been added. Exemplars were randomly chosen.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
For illustrative purposes, three exemplars per cluster (N = 21) were randomly selected. Table 3 shows the definitions of these exemplars alongside their cluster, the item in Chinese and a Hanyu Pinyin pronunciation.
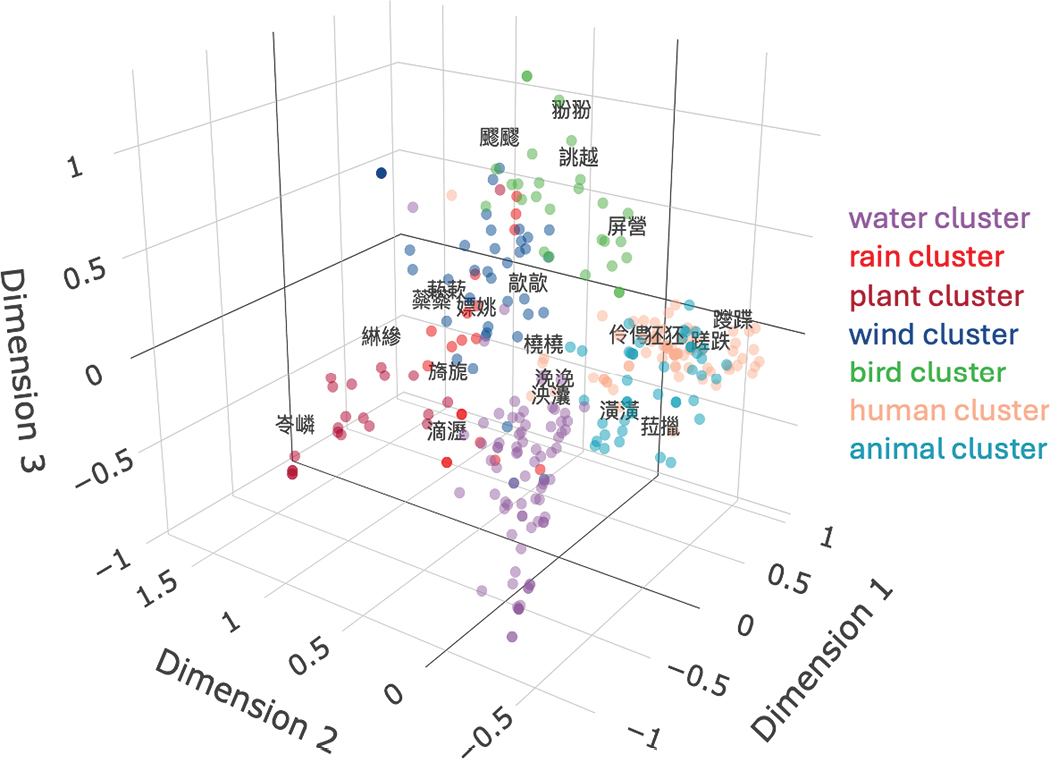
Finally, the literary Chinese motion ideophones are projected on a three-dimensional scatterplot (Figure 9), with the same exemplars highlighted for illustration. The points are colored according to their assigned cluster, showing that visually speaking, the clustering was successful. The scatterplot shows that at least three dimensions were necessary to understand the variance residing in the data, but also that these seven ontological domains projected onto the scattered points capture the clusters in a satisfactory manner.
Chinese literary ideophones (supplementary variables) projected on the first three dimensions of the mca analysis.
Citation: Cognitive Semantics 11, 2 (2025) ; 10.1163/23526416-bja10075
5 Conclusion and Outlook
In this study, we have investigated the category of literary Chinese motion ideophones and its internal configuration. Starting from the most granular perspective, we have found that there are about seven salient and meaningful clusters: water, rain, plant, wind, bird, human, and animal. Lexicological differences between the [human, animal] vs. [bird, wind, plant, rain, water] groups were apparent, and within that latter group splits between [bird, wind], [plant], and [rain, water] also emerged.
Zooming out, these differences were all correlated with different third-level component values that these words take within the motion semantic grid (Ibarretxe-Antuñano, 2019). By inspecting the first three dimensions of the Multiple Correspondence Analysis, it became clear that bundles of features tend to cluster together in a meaningful manner. For example, motion ideophones that have to do with human or animal motion have {human} and {animal} as their Basic level (figure). Their motor patterns are {walk} or {run} (manner) and run {along} or take a {zigzagging} path. Specific to Chinese, a handful of semantic radicals dominates these motion ideophones: {person 亻, foot 足, water 氵, mountain 山, silk 糸, wing 羽, wind 風}. Note that contrary to colloquial Chinese ideophones, where {mouth 口} is the dominating semantic radical (Thompson, 2018; Van Hoey & Thompson, 2020), the literary stratum is more diverse in its orthographic radical support.
Zooming even further out, we saw that not every second-level component contributes equally to the three most important dimensions of the Multiple Correspondence Analysis. Motor pattern, Basic level, Radical, Quanta, Animate, Direction, Type, Motion, Rate, and Aspect emerge as the most salient second-level components within these data. Curiously, it is at this level that the study successfully quantifies one of the major goals of the motion semantic grid as described by Ibarretxe-Antuñano (2019), namely identifying which second-level components are important for a given language. It does so in a way that goes beyond basic counting (as done in the original proposal). Instead, the more sophisticated approach of Multiple Correspondence Analysis takes the whole data set into account. Follow-up studies naturally follow from this approach: one could and should subject complete motion semantic grids for different languages (following the recommendations outlined in this study) to dimensionality reduction techniques like mca, followed by transformations that enable direct distance comparisons between motion ideophone inventories. In fact, this study is a first step toward such an approach that can then follow basic lectometric methods (for steps involved see, for instance, Geeraerts, Grondelaers & Speelman, 1999; Ruette, Ehret & Szmrecsanyi, 2016) to finally arrive at a multiple pairwise comparison between languages based on their motion ideophones. In fact, research along this pipeline is underway (by anonymized author).
This outlook for further understanding how motion is expressed through lexicalized depictions of course rests on the comparability between data. We can conclude that the motion semantic grid is a great framework that facilitates cross-linguistic comparability and is applicable to a large group of languages, provided that the data taken into consideration meets conditions sketched in the original chapter and in this study. It does seem, however, that the motion semantic grid has not yet arrived at a final fixed form that can then be universally applied to different languages. It is necessary to apply the grid first to a wider net of typologically diverse languages before we can get there. But the potential is definitely there.
Acknowledgments
I would like to acknowledge the guiding stars of this project, i.e., Kiyoko Toratani and Kimi Akita, for their encouraging comments during the process of developing and conducting this study. Also Iraide Ibarretxe-Antuñano, on whose shoulders I stand, deserves acknowledgments. Seeing this work in action at ninjal in 2016 provided enough inspiration to apply it to my own dataset of interest. Of course, sound boards are of the utmost importance to me: thank you CJ Young, Xiaoyu Yu and Yi Li for reading through this study. The usual disclaimers apply. fwo funding 1209725N is gratefully acknowledged.
References
Abdi, Hervé and Lynne J. Williams. 2010. Principal component analysis. wire s Computational Statistics 2(4): 433–459.
Akita, Kimi. 2012. Toward a frame-semantic definition of sound-symbolic words: A collocational analysis of Japanese mimetics. Cognitive Linguistics 23(1): 67–90.
Akita, Kimi and Mark Dingemanse. 2019. Ideophones (Mimetics, Expressives). In Mark Aronoff (ed.), Oxford Research Encyclopedia of Linguistics. Oxford: Oxford University Press.
Baxter, William Hubbard and Laurent Sagart. 1998. Word formation in Old Chinese. In Jerome Lee Packard (ed.), New Approaches to Chinese Word Formation: Morphology, Phonology and the Lexicon in Modern and Ancient Chinese, 35–76. Berlin; New York: Mouton de Gruyter.
Cao, Ruifang. 1995. Quantitative analysis of Mandarin Chinese abb adjectives. Linguistic Research 16(3): 22–25. (曹瑞芳, 1995, 普通话abb式形容词的定量分析,《语文研究》第3期:22–25。)
Chou, Ya-Min and Chu-Ren Huang. 2005. Hantology: An ontology based on conventionalized conceptualization. Proceedings of OntoLex 2005—Ontologies and Lexical Resources: 7–15.
Croft, William. 2012. Verbs: Aspect and Causal Structure. Oxford: Oxford University Press.
Dingemanse, Mark. 2012. Advances in the cross-linguistic study of ideophones. Language and Linguistics Compass 6(10): 654–672.
Dingemanse, Mark and Kimi Akita. 2017. An inverse relation between expressiveness and grammatical integration: On the morphosyntactic typology of ideophones, with special reference to Japanese. Journal of Linguistics 53(3): 1–32.
Geeraerts, Dirk, Stefan Grondelaers and Dirk Speelman. 1999. Convergentie en Divergentie in de Nederlandse Woordenschat: Een Onderzoek naar Kleding- en Voetbaltermen. Amsterdam: Meertens Instituut.
Glynn, Dylan. 2014. Correspondence analysis: Exploring data and identifying patterns. In Dylan Glynn and Justyna A. Robinson (eds.), Corpus Methods for Semantics: Quantitative Studies in Polysemy and Synonymy, 307–341. Amsterdam/Philadelphia: John Benjamins Publishing Company.
Greenacre, Michael. 2006. From simple to multiple correspondence analysis. In Michael Greenacre and Jörg Blasius (eds.), Multiple Correspondence Analysis and Related Methods, 41–76. London: Chapman & Hall.
Hamano, Shoko. 1998. The Sound-symbolic System of Japanese. Stanford, CA & Tokyo: CSLI Publications & Kurosio.
Hsieh, Shu-Kai. 2006. Hanzi, Concept and Computation: A Preliminary Survey of Chinese Characters as a Knowledge Resource innlp. Tübingen: Universität Tübingen Ph.D. dissertation.
Husson, François, Sébastien Lê and Jérôme Pagès. 2017. Exploratory Multivariate Analysis by Example Using R. Second edition. Boca Raton, Florida: CRC Press.
Ibarretxe-Antuñano, Iraide. 2004. Motion events in Basque narratives. In Sven Strömqvist and Ludo Verhoeven (eds.), Relating Events in Narrative, Volume 2: Typological and Contextual Perspectives, 89–112. Mahwah, NJ: L. Erlbaum Associates.
Ibarretxe-Antuñano, Iraide. 2019. Towards a semantic typological classification of motion ideophones: The motion semantic grid. In Kimi Akita and Prashant Pardeshi (eds.), Ideophones, Mimetics And Expressives, 137–166. Amsterdam/Philadelphia: John Benjamins.
Josse, Julie, Marie Chavent, Benot Liquet and François Husson. 2012. Handling missing values with regularized iterative Multiple Correspondence Analysis. Journal of Classification 29(1): 91–116.
Josse, Julie and François Husson. 2016. missMDA: A Package for Handling Missing Values in Multivariate Data Analysis. Journal of Statistical Software 70(1): 1–31.
Kassambara, Alboukadel and Fabian Mundt. 2020. factoextra: Extract and visualize the results of multivariate data analyses. https://CRAN.R-project.org/package=factoextra.
Kroll, Paul W. 2015. A Student’s Dictionary of Classical and Medieval Chinese. Leiden: Brill.
Kwak, Sang Kyu and Jong Hae Kim. 2017. Statistical data preparation: Management of missing values and outliers. Korean Journal of Anesthesiology 70(4): 407.
Langacker, Ronald W. 1987. Foundations of Cognitive Grammar 1: Theoretical Prerequisites. Stanford, California: Stanford University Press.
Langacker, Ronald W. 1991. Foundations of Cognitive Grammar 2: Descriptive Application. Stanford, California: Stanford University Press.
Lê, Sébastien, Julie Josse and François Husson. 2008. FactoMineR: An R package for multivariate analysis. Journal of Statistical Software 25(1): 1–18.
Levshina, Natalia. 2015. How to Do Linguistics with R: Data Exploration and Statistical Analysis. Amsterdam/Philadelphia: John Benjamins.
Li, Fuyin Thomas. 2018. Extending the Talmyan typology: A case study of the macro-event as event integration and grammaticalization in Mandarin. Cognitive Linguistics 29(3): 585–621.
Li, Jian. 2013. The Rise of Disyllables in Old Chinese: The Role of Lianmian Words. New York: The City University of New York Ph.D. dissertation.
Li, Yueyuan and Dan Ponsford. 2018. Predicative reduplication: Functions, their relationships and iconicities. Linguistic Typology 22(1): 51–117.
Lin, Jingxia. 2019. Encoding Motion Events in Mandarin Chinese: A Cognitive Functional Study. Amsterdam/Philadelphia: John Benjamins.
McLean, Bonnie. 2020. Revising an implicational hierarchy for the meanings of ideophones, with special reference to Japonic. Linguistic Typology 25(3): 507–549.
Mueller-Liu, Patricia. 2017. Onomatopoeia. In Rint Sybesma, Wolfgang Behr, Yueguo Gu, Zev Handel, C.-T. James Huang and James Myers (eds.), Encyclopedia of Chinese Language and Linguistics, vol. iii, 548–555. Leiden: Brill.
Nuckolls, Janis B. 1996. Sounds Like Life: Sound-Symbolic Grammar, Performance, and Cognition In Pastaza Quechua. New York: Oxford University Press.
Nuckolls, Janis B. 2014. Ideophones’ challenges for typological linguistics: The case of Pastaza Quichua. Pragmatics and Society 5(3): 355–383.
R Core Team. 2024. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Ruette, Tom, Katharina Ehret and Benedikt Szmrecsanyi. 2016. A lectometric analysis of aggregated lexical variation in written Standard English with Semantic Vector Space models. International Journal of Corpus Linguistics 21(1): 48–79.
De Schryver, Gilles-Maurice. 2009. The lexicographic treatment of ideophones in Zulu. Lexicos 19: 34–54.
Shi, Wenlei and Yicheng Wu. 2014. Which way to move: The evolution of motion expressions in Chinese. Linguistics 52(5): 1237–1292.
Slobin, Dan I. 2004. The many ways to search for a frog. In Sven Strömqvist and Ludo Verhoeven (eds.), Relating Events in Narrative, Volume 2: Typological and Contextual Perspectives, 219–257. Mahwah, NJ: L. Erlbaum Associates.
Sun, Jingtao. 1999. Reduplication in Old Chinese. Vancouver: University of British Columbia Ph.D. dissertation.
Talmy, Leonard. 2000a. Toward a Cognitive Semantics: Volumei: Concept Structuring Systems. Cambridge, MA: MIT Press.
Talmy, Leonard. 2000b. Toward a Cognitive Semantics: Volumeii: Typology and Process in Concept Structuring. Cambridge, MA: MIT Press.
Thompson, Arthur Lewis. 2018. Are tones in the expressive lexicon iconic? Evidence from three Chinese languages. PLOS ONE 13(12): 1–19.
Toratani, Kiyoko. 2012. The role of sound-symbolic forms in Motion event descriptions: The case of Japanese. Review of Cognitive Linguistics 10(1): 90–132.
Toratani, Kiyoko. 2024. Open-class-ness, aspect, iconicity, and other characteristics of Japanese ideophones viewed through the lens of closed-class semantics. Cognitive Semantics 10: 55–83.
Van Hoey, Thomas. 2018. Does the thunder roll? Mandarin Chinese meteorological expressions and their iconicity. Cognitive Semantics 4(2): 230–259.
Van Hoey, Thomas. 2023a. A semantic map for ideophones. In Thomas Fuyin Li (ed.), Handbook of Cognitive Semantics: Vol 2, 129–175. Leiden: Brill.
Van Hoey, Thomas. 2023b. abb, a salient prototype of collocate–ideophone constructions in Mandarin Chinese. Cognitive Linguistics 34(1): 133–163.
Van Hoey, Thomas. 2024. Onomatopoeia in Mandarin Chinese. In Lívia Körtvélyessy and Pavol Štekauer (eds.), Onomatopoeia in The World’s Languages: A Comparative Handbook, 563–575. Berlin: Mouton de Gruyter.
Van Hoey, Thomas and Arthur Lewis Thompson. 2020. The Chinese Ideophone Database (chideod). Cahiers de linguistique Asie orientale 49(2): 136–167.
Van Hoey, Thomas, Xiaoyu Yu, Tung-Le Pan and Youngah Do. 2024. What ratings and corpus data reveal about the vividness of Mandarin abb words. Language and Cognition 16(4): 1674–1696.
Vendler, Zeno. 1957. Verbs and times. The Philosophical Review 66(2): 143–160.
This paper uses traditional characters throughout. However, for the data that is analysed, a conversion datasheet with traditional and simplified characters is provided in the supplementary materials on the osf repository.
All data and scripts can be found in the following osf repository: https://osf.io/qfr95/






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}