Abstract
Teachersâ accurate classification of cognitive demand is essential when developing assessment instruments. This study examined Malaysian science teachersâ proficiency in classifying 30 science multiple-choice questions (MCQâs) according to the revised Bloomâs taxonomy (RBT) and the Structure of the Observed Learning Outcome (SOLO) taxonomy. Classifications were conducted over three rounds using the bookmark procedure, with revisions after discussion. Initial agreement was low, improving to moderate in the second. During the discussions, some teachers displayed professional judgement, while others were influenced by personal interpretive tendencies. Final classifications were compared to those of the research team, showing higher agreement for RBT than for the SOLO taxonomy. Most panelists demonstrated varied accuracy in individual item classification. A chi-square test revealed significant association (
1 Introduction
Malaysian science teachers are required by policy to construct their own test items, including multiple-choice questions (MCQâs) according to a cognitive difficulty distribution aligned with the revised Bloomâs taxonomy (RBT; Ministry of Education [MOE], 2016). The Ujian Akhir Sesi Akademik (Final Exam of the Academic Session) mandates two key requirements for assessment design: (1) 50% of items must assess higher-order thinking skills (HOTS; MOE, 2013), and (2) the difficulty distribution must follow the ratio of 50% easy, 30% moderate difficulty, and 20% high difficulty (MOE, 2021). However, research has shown that teacher-authored MCQâs often contain technical or cognitive flaws, resulting in low validity, poor discrimination indices, and misalignment with the curriculum standards (Gani & Abdullah, 2011; Husin, 2020).
Alternative taxonomies, such as the Structure of the Observed Learning Outcome (SOLO; Biggs & Collis, 1982) are also used for item classification, but this taxonomy remains relatively unknown in Malaysia. Given that teacher-generated tests count for qualification decisions, it is important to examine whether teachers can accurately classify levels of cognitive demand according to the RBT. Using the bookmark procedure for standard setting, online panels of Malaysian science teachers classified item cognitive demand using both the RBT and SOLO taxonomy. This study contributes to our understanding of factors impacting teachersâ ability to identify the cognitive processes involved in answering MCQ test questions.
1.1 Revised Bloomâs Taxonomy
Multiple taxonomies have been developed to provide structured frameworks for articulating the mental processes elicited by assessment tasks and to guide their design, classification, and analysis (Irvine, 2021). Bloomâs (1956) pioneering cognitive taxonomy was originally intended to assist teachers in formulating lesson plans, learning objectives, and assessment instruments. The taxonomy conceptualized cognitive complexity as a cumulative hierarchy consisting of six levels, ranging from simple to complex, knowledge, comprehension, application, analysis, synthesis, and evaluation, with each level building upon the preceding one (Krathwohl, 2002). Bloomâs framework played a key role in standardizing the design of cognitive demand within item development across institutions. It has since been widely applied across educational levels for various purposes, including the creation of test items, learning objectives, instructional guidance, and assessment types (Krathwohl, 2002).
However, the taxonomy has faced criticism for its unidimensional structure, broad generalizations of cognitive dimensions, and lack of clear guidance for determining cognitive levels (Krathwohl, 2002). For instance, the overlap between knowledge and comprehension complicates item classification (Lemons & Lemons, 2013; Marzano & Kendall, 2007). Additionally, its rigid hierarchical order is problematic. For example, some evaluations can occur without synthesis skills, despite evaluation being positioned at the highest level (Crowe et al., 2008). These critiques prompted revisions to the arrangement of upper cognitive levels (Kim et al., 2012), culminating in the development of a revised version.
The Revised Bloomâs Taxonomy (RBT) was created in 2001 when Anderson and Krathwohl established a two-dimensional framework comprising the cognitive and knowledge dimensions. Similar to the original taxonomy, the cognitive dimension is arranged hierarchically, progressing from simple to complex but expressed in verb form: remembering, understanding, applying, analyzing, evaluating, and creating. The knowledge dimension is arranged from concrete to abstract: factual, conceptual, procedural, and meta-cognitive. This version emphasized classifying educational objectives as two-dimensional guidelines (Krathwohl, 2002) that could enhance teaching quality by helping teachers understand the curriculum, plan instruction, and design assessments that align with the objectives better (Anderson & Krathwohl, 2001).
The hierarchical order of the six levels is distinguished by degrees of difficulty (Marzano & Kendall, 2007). In this version, the levels were renamed using verbs to reflect the active nature cognitive processes, and the top two levels were changed from synthesis and evaluation to evaluating and creating. The change highlighted that while typically requires both critical and creative thinking, evaluation may not always involve synthesis skills (Crowe et al., 2008).
RBT features prominently in Malaysiaâs educational policies and official documents. It is the recommended framework for developing assessment items and instruments in the Malaysia Education Blueprint (MOE, 2013). Its six levels describe student performance and inform performance indicators in the Dokumen Standard Kurikulum dan Pentaksiran (Standard Curriculum and Assessment Document; MOE, 2017). Additionally, this taxonomy distinguishes between lower-order thinking skills (LOTS) and higher-order thinking skills (HOTS), with the top four levels, applying, analyzing, evaluating, and creating, representing HOTS (MOE, 2016). The latest guidebook for creating HOTS-level items, Panduan Pembinaan Item Kemahiran Berfikir Aras Tinggi (Guide to Developing Higher-Order Thinking Items), uses these top four levels to guide item development (Lembaga Peperiksaan, 2023). Given its prominence in policy documents, it is unsurprising that teachers are more familiar with this framework. However, such widespread adoption may lead teachers to regard it as the primary or even exclusive framework for instructional practices. Numerous local studies on item classification and development have also favored the use of RBT (Abu Hassan et al., 2020; Aisyah et al., 2019; Hassan et al., 2017; Jamalludin & Zamzuri, 2018; Singh & Shaari, 2019; Tee et al., 2012; Zaiful Shah & Zakaria, 2024; Zulkifli & Abidin, 2022). The taxonomyâs verb lists are particularly appealing to teachers, as they offer practical guidance for lesson planning and assessment design. Consequently, RBT continues to be widely preferred and extensively used.
This version has been adopted and implemented across diverse countries, regardless of sociological and political contexts, and across all educational levels and subjects. RBT has been applied to analyze and classify science curricula objectives and standards in different countries, such as South Korea and Singapore (Lee et al., 2015), Mainland China, Taiwan, Macao, and Hong Kong (Wei & Ou, 2019), and chemistry curricula in Czechia, Finland, and Türkiye (Elmas et al., 2020). Internationally, RBT is widely applied in the creation and classification of assessment items across education systems (Lemons & Lemons, 2013; Motlhabane, 2017; Phillips et al., 2013; Zulkifli & Abidin, 2022).
Nonetheless, RBT continues to face several challenges. Marzano and Kendall (2007) argued that it lacks comprehensive tools necessary to assess higher-order thinking. For example, some verbs may not align with the intended cognitive demands, leading to misinterpretation (Zulkifli & Abidin, 2022). Teachers have commonly used RBT to classify cognitive demand due to its detailed verb lists that aid in item development and categorization (Lemons & Lemons, 2013). However, this reliance can be limiting, especially when inappropriate verbs are used to represent the intended cognitive processes (Thompson, 2008). Therefore, the ability to evaluate the relevance of verbs is essential for accurately understanding cognitive demand (Sangodiah et al., 2014). Teachers must independently evaluate whether the selected verbs reflect the intended level of thinking, as there is no direct association between verbs and cognitive processes (Larsen et al., 2022). Understanding the taxonomyâs structure alone is insufficient; teachers must also grasp the intent behind each question. This is particularly important in crafting MCQâs that assess more than simple recall (Thompson, 2008).
The limitations that led to the development of the RBT prompted the emergence of alternative taxonomies, such as the Structure of the Observed Learning Outcome (SOLO) taxonomy (Biggs & Collis, 1982), Marzano and Kendallâs (2007) New Taxonomy, and Webbâs (1997, 1999) Depth of Knowledge. Research has shown that frameworks like SOLO provide a more detailed structure for developing and assessing studentsâ critical thinking (Lee et al., 2017). Unlike RBT, the SOLO taxonomy provides a clearer means of evaluating different levels of cognitive processing, making it a valuable tool for both assessment and instruction.
1.2 The SOLO Taxonomy
The SOLO taxonomy (Biggs & Collis, 1982) emerged as a neo-Piagetian model (Piaget, 1950), due to its constructivist roots and its description of learning as a developmental progression. The SOLO taxonomy identified four meaningful levels of cognitive demand or capability: unistructural, multistructural, relational, and extended abstract. This framework considers at least four structural and psychological factors in determining the learnerâs cognitive development or the cognitive demand of tasks or products (Hattie & Purdie, 1998).
In terms of psychological processes, increasing levels within the SOLO taxonomy require increasing demand on working memory or attention span: Unistructural tasks require attention to one element, multistructural to two or more elements, relational to the connection among two or more elements, and extended abstract to generalization beyond given information. The SOLO taxonomy also addresses two opposing cognitive needs: consistency and closure. The drive for closure may lead a learner to ignore important information in order to reach an answer more quickly, resulting in a lower-level response. In contrast, a drive for consistency may prompt greater effort to ensure a response aligns with the demands of a task or prompt.
In parallel, structural characteristics of a task influence the outcome produced by the learner. The size of the task (e.g., list three causes of air pollution) determines the cognitive demand and shapes the parameters of the response. The qualitative shift from listing objects, unistructural or multistructural, requires learners to focus on how the various elements in a task space relate to one another. In this sense, the SOLO taxonomy presents a progressive hierarchy that connects task demand with psychological resources, motives, and individual goals. It suggests that cognitive development is dynamic and context-dependent, progressing at different rates across individuals (Biggs & Collis, 1982).
The SOLO taxonomy shifted the focus from cognitive development alone to the complexity of learning outcomes, using studentsâ tangible and measurable responses to evaluate their development (Biggs & Collis, 1989). In educational settings, particularly assessment, the SOLO taxonomy is well-suited for describing learning complexity as it progresses from surface to deep levels across quantitatively and qualitatively distinct levels.
The SOLO taxonomy has been described as âa language for describing the level and quality of learning both within and across the curriculumâ (Biggs & Collis, 1989, p. 151). It serves as a framework for assessing student responses and classifying them based on its four-level structure. This feature helps teachers to enhance student learning by analyzing their responses. For example, science teachers use the SOLO taxonomy to identify and improve problem-solving skills (Collis & Davey, 1986), while English teachers apply it to foster understanding and critical thinking (Ibrahim Badr, 2020). In mathematics, the framework helps describe studentsâ abilities in mathematical representations (Trapsilasiwi et al., 2020). In higher education, it has served as a tool for scaffolding, assessing, and fostering deep learning (Boulton-Lewis, 1995; Lucander et al., 2010). Beyond classroom teaching, the SOLO framework has been used to classify studentsâ postings in asynchronous online discussions, helping educators evaluate understanding and engagement (Holmes, 2005). Additionally, it has informed the design of teacher training interventions aimed at improving teaching effectiveness and student outcomes (Hattie, Biggs, & Purdie, 1996; Hattie & Brown, 2004).
Although less widely used in Malaysia (Weay et al., 2016), the SOLO taxonomy has been applied in several studies to analyze student responses in across a variety of subjects and educational levels (Abdul Aziz, 2022; Idek, 2016, 2020; Lim et al., 2010; Lim & Wun, 2011; Mohd Nor & Idris, 2010; Weay et al., 2016), as well as to improve student learning (Idek, 2020; Prakash et al., 2010; Tan, 2006). Nonetheless, after extensive searches across major academic databases, including Web of Science, Scopus, Education Research Complete, and Google Scholar, very few studies were found in Malaysia that specifically applied the SOLO taxonomy for item classification.
1.3 The Relationship between RBT and the SOLO Taxonomy
Both RBT and the SOLO taxonomy follow a hierarchical structure that reflects the principle of growth in learning, from simple to complex. Generally, both frameworks are applicable across all educational levels and subjects, and are useful for planning learning objectives, guiding instructional strategies, and identifying the cognitive demands of assessment tasks. They provide a basis for aligning assessments with intended learning outcomes.
However, empirical studies (see review in Hattie & Purdie, 1998) have indicated that results often differ when applying these taxonomies in cognitive classification (Weay et al., 2016). RBT appears more suitable for thinking about curriculum and learning objectives prior to the assessment stage (Adams, 2015; Anderson & Krathwohl, 2001). Unfortunately, RBT is not designed to track student learning growth, which is essential in science education (Lee et al., 2017). Additionally, some science teachers struggle to recall or explain the higher cognitive levels in the taxonomy (Hassan et al., 2017). Research has also shown that teachers often face challenges with item classification due difficulties interpreting the underlying cognitive processes (Hassan et al., 2017; Omar et al., 2012; Zulkifli & Abidin, 2022). Hence, despite the longevity of RBT in Malaysia, it remains poorly understood by many teachers.
In contrast, the SOLO taxonomy can be applicable in both curriculum design and assessment design and plays a distinct role in evaluating learning outcomes and student understanding (Caridade & Pereira, 2023; Hattie & Brown, 2004). The SOLO taxonomy allows for the independent analysis of student responses, separate from design tasks (Gillies, 2020; Hattie & Purdie, 1998). It is not limited to designing tasks or test items; rather, it is particularly effective in analyzing learning progress, especially in open-ended contexts (Biggs & Collis, 1982). The ability to classify task demand independently from student response makes the SOLO taxonomy especially useful for tracking student progress and learning growth (Biggs & Tang, 2011). Furthermore, its simplicity enables teachers to the levels to provide descriptive feedback and to help students construct more complex and relational responses over time (Chan et al., 2002; Pegg & Tall, 2005).
Although RBT is the required taxonomy for test development in Malaysia, there are good reasons to believe that the SOLO taxonomy might be easier for teachers to use. In New Zealand, high school mathematics and English teachers were able to apply the SOLO taxonomy effectively, after brief training, to identify the cognitive demands of MCQ test items (Hattie & Brown, 2004). Based on these findings, this study examined how accurately Malaysian science teachers could classify the cognitive demand of MCQâs using both RBT and the SOLO taxonomy. Given the novelty of the SOLO taxonomy relative to the RBT, we expected that classification accuracy to be higher with RBT. However, given the simplicity of the SOLO taxonomy, we also expected that basic training would enable comparable levels of classification accuracy. Thus, the study evaluated both taxonomies.
2 Objectives of the Study
While policy mandates require Malaysian teachers to align item difficulty with cognitive complexity, this remains a significant challenge due to the absence of validated item banks at both national and local levels. Without such resources, teachers lack a reliable benchmark for evaluating school-developed items against official standards, raising concerns about the accuracy of difficulty ratings. Even when schools develop internal item banks, without documented validation (e.g., statistical analysis of student performance), cross-item comparisons remain speculative and potentially unreliable.
Currently, RBT is the primary framework used in the Malaysian education system to classify cognitive demand. However, its emphasis on task verbs and hierarchical processes can result in oversimplified interpretations of cognitive demand. In contrast, the SOLO taxonomy focuses on the structural complexity of student thinking, offering a qualitatively different perspective. Comparing these two taxonomies allows for an evaluation of whether different classification systems produce consistent interpretations of cognitive demands in MCQâs. This study applied both frameworks to examine classification consistency and assess the potential of the SOLO taxonomy as a complementary tool to strengthen science assessment practices.
2.1 Research Aims
Given the documented difficulties teachers face in using the RBT to classify science test items, this study was designed to address three key research questions:
To what extent do teachersâ ratings of cognitive demand agree when using RBT versus the SOLO taxonomy?
How closely do teachersâ classifications align with those made by the research team?
Do RBT and SOLO classifications correspond with each other when grouped into broader categories of lower- and higher-order thinking?
2.2 Hypotheses
The study tests the following hypotheses:
H1. Science teachers will demonstrate moderate to high agreement and inter-rater reliability when classifying the cognitive demands of science MCQâs using the RBT. SOLO taxonomy classifications will yield lower agreement, reflecting its relative unfamiliarity among teachers.
H2. Science teachersâ classifications will show strong alignment with those of the research team.
H3. When levels are grouped into lower- and higher-order thinking, there will be a statistically significant relationship between RBT and SOLO taxonomy classifications.
By applying both RBT and the SOLO taxonomy, this study introduces a novel dual-framework approach to evaluating cognitive demand in Malaysian science education, offering new possibilities for improving item design and assessment validity.
3 Methods
This study used a structured training (intervention only, without a control group) design to familiarize participants with the RBT and SOLO taxonomy, as well as item difficulty according to official Malaysian protocols. Two separate sessions were conducted to minimize confusion between the RBT and SOLO taxonomy. After training, participants were organized into panels and asked, following the bookmark procedure, to individually classify preselected science MCQâs by difficulty and cognitive levels, followed by group discussion. Data were evaluated at the end of each round, and consensus and consistency statistics were calculated (Stemler, 2004). Additionally, the panelistsâ bookmarks were compared to the classifications of the research team.
3.1 Participants
A convenience sample was recruited from a restricted online Telegram group for Malaysian science teachers, used to share information and teaching materials. Following ethics approval from the institutional board, workshops were conducted via Zoom. Recruitment was limited to teachers with at least 5 years of experience teaching science at the lower secondary level, to ensure sufficient expertise. In total, seven science teachers, all with experience in writing school-level assessment items, were recruited. While all seven participated in the RBT session, only four were available for the SOLO taxonomy session. Only one participant had national-level item-writing experience. Two participants taught in high-performing schools; the others taught in national secondary schools across Malaysia. All panelists held at least a bachelorâs degree; one was pursuing a masterâs. All had a minimum of 5 years of teaching experience and had taught science as their primary subject. Session 1 included all seven teachers; Session 2 include four who had also participated in the first session.
3.2 Materials
The study used 30 MCQâs from the 2013 Penilaian Menengah Rendah (Lower Secondary Assessment) (Lembaga Peperiksaan, 2013) and 2019 Penilaian Tingkatan Tiga (Form Three Assessment) (Lembaga Peperiksaan, 2019a). These were the final standardized science assessments before the Penilaian Menengah Rendah was discontinued in 2014 (Kang, 2014) and the Penilaian Tingkatan Tiga was postponed in 2020 and 2021 due to the COVID-19 pandemic (BERNAMA, 2020). Both assessments were developed by the Lembaga Peperiksaan (Examination Syndicate) (Lembaga Peperiksaan, 2019b), making them reliable and valid measures of science knowledge at the end of lower secondary education (Form 3, age 15).
A single set of 30 MCQâs was used to create two versions of an ordered item booklet (OIB). To reflect thematic organization of the curriculum, the items were grouped into four overarching science themes: (1) maintenance and continuity of life (10 items), (2) exploration of elements in nature (11 items), (3) energy and sustainability of life (5 items), and (4) exploration of Earth and space (4 items). Each theme drew on content from learning areas across Forms 1 to 3 (ages 13 to 15). In total, seven items were from the Form 1 syllabus, 15 from Form 2, and eight from Form 3. The assessment items used in this study were drawn from the Ordered Item Booklet (Version 6), which contains a selection of science multiple-choice questions aligned with curriculum standards. The full dataset is openly available and was archived by the author (Sirri, 2025) in the University of Aucklandâs Figshare repository.
The two booklets were then structured according to the two theoretical taxonomies. In the RBT version, items were categorized into three difficulty levels: low (k = 14), moderate (k = 12), and high (k = 4). In contrast, the SOLO taxonomy version categorized items by structural complexity into four levels: unistructural (k = 14), multistructural (k = 1), relational (k = 13), and extended abstract (k = 2). The content remained identical across both versions. However, to align with the different theoretical perspectives on taxonomic difficulty, seven items appeared in a slightly different sequence in the SOLO taxonomy booklet (e.g., Item 9 in the RBT version appeared as Item 8 in the SOLO version). Prior to the sessions, expert teachers cross-checked the item order, and minor adjustments were made.
3.3 The Bookmark Procedure
This study employed the bookmark procedure (Mitzel, Lewis, & Green, 2001) for standard setting. The procedure was implemented across two separate sessions, each comprising three structured rounds: individual, small panel, and full panel. In each round, panelists set cut scores to mark transition between taxonomic or difficulty levels and recorded the item numbers on a form.
In the individual round, panelists worked independently and recorded their placements without discussion. In Session 1, seven panelists were split into two groups of three and four. In Session 2, four panelists were divided into two pairs. In the small group round, panelists compared their bookmark placements, discussed their reasoning, and worked towards consensus. The discussion helped clarify discrepancies and refine understanding of item classifications. Finally, in the full panel round, all panelists in the session finalized their placements. Items with disagreement were revisited and justifications provided. This consensus-building process ensured that all viewpoints were considered.
Session 1 used RBT classifications based on difficulty level (low, moderate, and high), while Session 2 used the SOLO taxonomy, which included four levels of structural complexity.
3.4 Protocol
The bookmark procedure was piloted with five qualified Malaysian science teachers. After a brief presentation on the procedure and the two cognitive taxonomies, panelists rated 30 MCQâs from the OIB using a Google Form. The briefing slides received positive feedback, and the form was considered user friendly. Panelists found the timing appropriate but recommended more active facilitation, especially in Round 3.
To avoid confusion between the two taxonomies, sessions were held one week apart, using the same group of panelists. Session 1 used the RBT version, and Session 2 used the SOLO taxonomy version, each with its corresponding OIB. This within-subject design enabled direct comparison of how the same items were classified under both frameworks while controlling for content differences. Each session included a 20-minute taxonomy briefing and three rounds of the bookmark procedure. The full procedure lasted approximately 2 hours pers session, with the lead author facilitating discussions in Rounds 2 and 3.
3.5 Interrater Reliability
Consensus on bookmark placements was defined as at least 67% of panelists assessing the same item to the same level transition (Karantonis & Sireci, 2006). The kappa coefficient (
3.6 Cross-Taxonomy Comparison
To compare classifications across two taxonomies, item ratings were grouped into lower- and higher-order categories. A chi-square test was used to evaluate the relationship between the RBT and SOLO taxonomy classifications. Although traditional guidelines recommend a minimum expected cell frequency of five, this threshold is considered arbitrary (Howell, 2011). Simulations by Campbell (2007) showed that chi-square tests remain valid with expected frequencies as low as one. Therefore, this test was considered appropriate given the small sample size and categorical nature of the data.
3.7 Qualitative Insights
Panelist discussions during Rounds 2 and 3 were recorded and transcribed to gain qualitative insight into their reasoning and negotiation processes. Although formal thematic analysis was not conducted, a qualitative content review was performed. Transcripts were manually reviewed, and representative excerpts were selected to illustrate key themes, and shifts in consensus across rounds.
4 Results
The results of the two taxonomies are presented along with selected discussion comments, in the order of the taxonomy sessions (i.e., RBT, followed by the SOLO taxonomy). Comments from the panel discussions were recorded to provide insights into the observed levels of agreement.
4.1 First Session: RBT
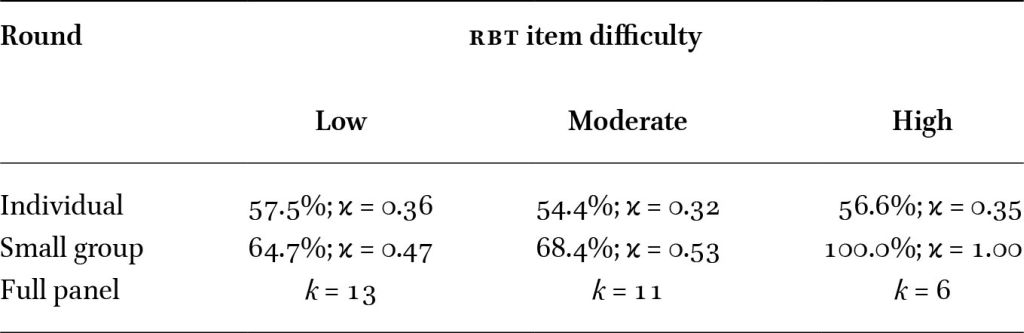
In this session, panelists showed weak to moderate agreement during the transition from individual scoring to small group discussions (see Table 1). In Round 1, individual bookmark placements showed weak agreement across all taxonomic levels (< 67% agreement,

Inter-rater agreement on RBT item difficulty classifications by bookmarking round
Citation: Asia-Pacific Science Education 11, 2 (2025) ; 10.1163/23641177-bja10101
During the full panel discussion, determining cut scores for low- and moderate-difficulty items took longer than for high-difficulty items. This supports findings by Perez et al. (2012), who reported that distinguishing lower cognitive levels, often associated with low- and moderate difficulty items, is more challenging than identifying high-difficulty ones. For example, panelists debated Item 10: Group 1 classified it as low-difficulty, while Group 2 considered it to be of moderate-difficulty. Group 2 argued that the item required âdouble loops of thinking,â indicating higher cognitive demands, whereas Group 1 maintained that it involved only remembering and understanding, consistent with the second level of the taxonomy. In contrast, agreement on Item 27 was reached quickly. Both groups identified it as requiring inferencing, which aligned with its classification as a high-difficulty item.
4.2 Second Session: the SOLO Taxonomy
The second session r low initial agreement in the individual ratings (see Table 2). In Round 1 there was minimal consensus and weak chance-adjusted agreement across levels (< 50% agreement,
Inter-rater agreement on SOLO taxonomy cognitive demand classifications by bookmarking round
Citation: Asia-Pacific Science Education 11, 2 (2025) ; 10.1163/23641177-bja10101
The increased agreement between individual and group rounds likely resulted from the collaborative nature of the discussions, which helped panelists align their classifications (Geisinger & McCormick, 2010), despite their limited prior experience with the SOLO taxonomy. For example, during the full panel discussion in Round 3, Group 2 initially did not classify any items at the extended abstract level. However, after hearing Group 1âs justification for classifying an item involving growth curve analysis as higher-order thinking, Group 2 maintained their view that it required analytical skills based on textbook descriptions, but not cross-disciplinary abstraction. The final classification reflected Group 2âs interpretation. In contrast, for Item 27, Group 1 explained that the task required students to engage in problem solving by understanding the effects of temperature on matter. This led Group 2 to reconsider and ultimately agree that the task involved predictive reasoning. As a result, Items 27 to 30 were classified at the extended abstract level.
4.3 Comparing Classifications of Teacher Panels with the Research Team
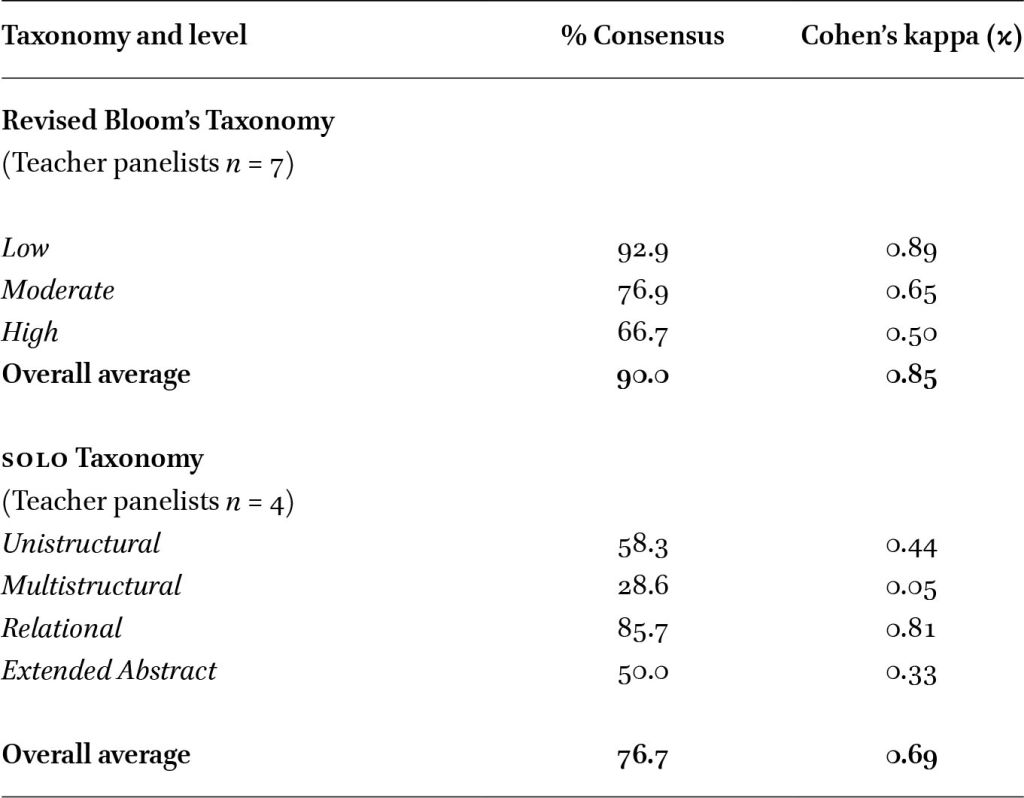
The final classifications from the full panels were compared to those of the research team using Cohenâs kappa (Table 3). Agreement levels were strong when using the RBT (90% agreement,
Comparison of agreement between teacher panel and research team ratings by taxonomy and cognitive level
Citation: Asia-Pacific Science Education 11, 2 (2025) ; 10.1163/23641177-bja10101
Notably, one panelist asked whether the structural complexity of the answer choices should also be considered in classification. This indicated awareness of an additional dimension beyond verb choice. This moment reflects a broader interpretive challenge: the SOLO taxonomy requires judgements about the depth of understanding demonstrated in a response, a perspective that may be unfamiliar for teachers more accustomed to the verb-driven classification style of RBT. The structural focus of the SOLO taxonomy introduces interpretive challenges, particularly for teachers with limited exposure to the framework. Making abstract judgements about depth of knowledge, rather than simply matching cognitive levels to the verbs, can be difficult. Nonetheless, this outcome might have been anticipated given, the relative unfamiliarity of the SOLO taxonomy in Malaysia, where it has not been widely adopted or understood, especially in the context of item classification.
4.4 Comparing the Classification of LOTS vs HOTS between Teacher Panels and the Research Team
Further analysis examined the relationship between the two taxonomies in classifying items as lower-order thinking skills (LOTS) or higher-order thinking skills (HOTS). Four teachers participated in both taxonomy sessions. To simplify analysis, items were grouped into two categories: lower order vs higher order. In the RBT, low-difficulty items align with LOTS, while moderate- and high-difficulty items correspond to HOTS. Similarly, in the SOLO taxonomy, unistructural and multistructural items reflect surface-level learning (LOTS), whereas relational and extended abstract items indicate deep-level learning (HOTS).
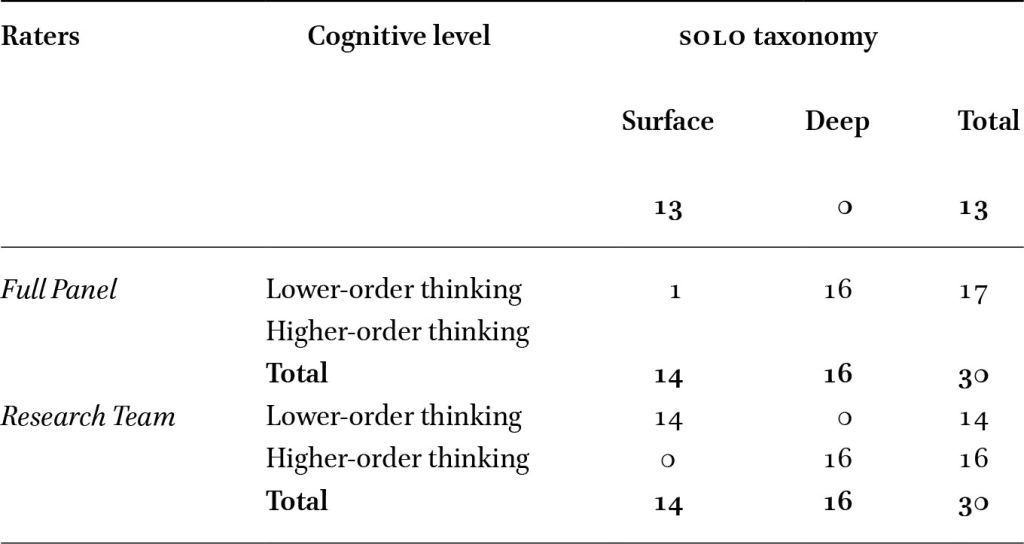
Table 4 shows the number of items classified at LOTS and HOTS by both science teacher panels and the research team. A chi-square test of independence showed a significant association between the two taxonomies in the teacher panel classifications (
Comparison of item classifications by the full teacher panel and the research team using RBT and SOLO taxonomies
Citation: Asia-Pacific Science Education 11, 2 (2025) ; 10.1163/23641177-bja10101
For instance, while classifying Item 22, one panelist remarked:
Yes, this item is moderately difficult, but we felt it was difficult because we thought it might be challenging for our students.
Despite repeated prompts to focus on cognitive processes, teachers were often influenced by contextual factors, such as school setting and student access to resources. One Group 2 panelist noted:
I felt that we cannot generalize our school experiences to all students. Like me, teaching in an island, itâs easy to find a shell for the experiment, but in a rural or mountainous areas, this is not feasible.
These context-driven perspectives, shaped by teachersâ backgrounds and school environments (Engelhard Jr., 2011), reflected subjective interpretations that occasionally led them to misclassification. Although these views were grounded in real classroom experience, they sometimes resulted in compromised the validity of assessment classification. While item classification should ideally be systematic and unbiased (Xu & Brown, 2016), it is often affected by human factors, including professional experience, context, and interpretation (Cicchetti & Feinstein, 1990). The inconsistencies observed in this study underscore the need for structured training and clearly defined guidelines to reduce subjectivity and improve reliability of item classification.
5 Discussion
The findings show that H1 was supported: teachers classified items more accurately with the RBT than with the SOLO taxonomy. However, two rounds of panel discussion led to high agreement within the SOLO taxonomy for the LOTS levels of unistructural and multistructural categories. In terms of H2, strong agreement was found between teacher panels and the research team only for the RBT, with much lower agreement for the SOLO taxonomy. As expected in H3, agreement was very high between panels and researchers when both frameworks were reduced to the broader categories of surface (LOTS) and deep (HOTS) learning. Overall, these results reflect teachersâ greater familiarity with the RBT and the relative simplicity of the binary LOTS-HOTS distinctions.
5.1 Teachersâ Ratings of Item Cognitive Demands
The lack of consensus among panelists highlights the influence of professional judgement and personal interpretation. Rather than relying solely on taxonomy criteria, teachers frequently drew on intuitive understandings of their studentsâ abilities. This reliance on informal reasoning led to divergent decisions and idiosyncratic interpretations, as illustrated in the results section.
The disagreements, often rooted in differing teaching backgrounds and interpretations of cognitive demand (Cicchetti & Feinstein, 1990; Engelhard Jr., 2011), were gradually mediated through structured discussion and collaborative reflection. These interactions fostered shared understanding and clarified ambiguities in the taxonomies, highlighting the value of dialogic engagement in professional learning (Richardson, 1998).
Teachers showed more consistent classifications with RBT than with the SOLO taxonomy. This pattern likely reflects long-standing exposure to RBT through policy documents, training materials, and daily teaching practice. Familiarity created a shared heuristic and a common language for judging item intent, narrowing variation across raters. By contrast, classifications using the SOLO taxonomy were more variable. The SOLO taxonomy requires raters to evaluate the structural complexity of student responses rather than labeling processes with verbs. This shift is conceptually demanding and particularly challenging to apply to MCQâs, which lack extended responses.
Greater consistency, however, should not be interpreted as greater validity. It may instead reflect alignment with a familiar framework rather than a more accurate construct representation. Effective classification depends not only on theoretical familiarity, but also on teachersâ content knowledge and awareness of national assessment standards and practices. This broader pedagogical assessment knowledge, which combines theory, subject matter expertise, and awareness of testing conventions, is essential for valid classification, but cannot be assumed, even among experienced educators or university-level instructors. In Malaysia, where assessment responsibilities are decentralized and validated items banks are limited, these challenges are acute (Koh, 2011). As Brookhart (2010) argued, the diagnostic value of assessment depends on the quality of its tools, and poorly constructed items can risk distorting student outcomes and compromise instructional decision-making. These findings reinforce the need for structured, sustained training that integrates theory, subject matter knowledge, and contextual expertise in assessment design and evaluation.
5.2 Comparing RBT and the SOLO Taxonomy
RBT assumes that both question and answer reflect the same cognitive level. In contrast, the SOLO taxonomy allows for variations in student responses within the same task. For example, a relational-level question may elicit either multistructural or relational levels, depending on the learner. This flexibility captures student thinking more precisely and offers richer, individualized feedback (Biggs & Collis, 1982). While RBT is widely used for designing assessment items, the SOLO taxonomy provides a framework for evaluating the depth of student responses after assessments are administered.
In this study, analysis focused on how teachers classified science MCQ items using both taxonomies. Given the absence of student response data, judgments depended on item structure and answer choices. Teachers appeared influenced by how options were framed, as these often signaled recall or reasoning demands. In MCQ design, such cues can subtly shape teachersâ perceptions of cognitive complexity.
The common reliance on action verbs in RBT also contributed to misinterpretations. Although convenient, verbs can be ambiguous (Mohamed et al., 2019) and imprecise (Zulkifli & Abidin, 2022). Accurate classification requires analyzing the task demands and reasoning involved. Over emphasis on surface features risks misalignment between test items and intended learning outcomes.
Unsurprisingly, teachers working with the SOLO taxonomy for the first time, struggled at the individual item level, especially at the multistructural tasks. At the aggregate LOTS vs HOTS level, however, performance improved. This suggest that while the SOLO taxonomy offers greater conceptual depth, significant professional development would be required for accurate application in Malaysia.
At this broader level, science teachersâ judgements were consistent with the research teamâs ratings. This finding suggests that teachers can reliably classify items into LOTS and HOTS, even if they struggled with finer distinctions. Given the demands of classroom practice, such aggregate categories may be sufficient for item writing and classification. Expecting teachers to consistently apply more fine-grained distinctions may be unrealistic without specialized training.
6 Implications and Future Research
The challenges identified in this study, including interpretive inconsistencies, reliance on intuition, and uneven familiarity with taxonomies, are not unique to Malaysian science teachers. Similar issues are likely to arise wherever teachers are responsible for classroom-based assessments, especially for high-stakes qualifications. Future research should investigate whether these challenges stem from systemic training gaps, resource limitations, or curriculum pressures, and how these factors vary across different cultural and policy contexts. Comparative and longitudinal studies could further explore the impact of integrated RBT-SOLO training on classification accuracy and item quality. Additionally, examining teachersâ cognitive decision-making when classifying items may reveal sources of misinterpretation, helping to design professional learning models adaptable across education systems.
7 Conclusion
This study showed that, without training or discussion, Malaysian science teachers struggled to accurately classify the cognitive demand of science MCQâs. The findings revealed the intuitive and idiosyncratic processes teachers relay on when evaluating their own students, raising legitimate concerns about the robustness, fidelity, and reliability of the Malaysian examination system. However, when teachers worked with a familiar taxonomy, or when classifications were reduced to the binary LOTS-HOTS distinction, they were able to classify items more accurately. The study does not claim that accurate identification of demand directly leads to robust item writing. Nonetheless, if teachers cannot reliably judge the type of thinking required in an MCQ, it is unlikely that students will be accurately assessed. Without accurate testing, decisions about student promotion and qualification are vulnerable to error. Thus, the credibility of the Malaysian qualification system, in its distributed structure, warrants scrutiny.
Fortunately, the study also shows that structured training and collaborative discussion around real test items can provide an effective professional development process that should be deployed across the system. Speculatively, these findings have implications not only for Malaysia, but also for other education systems, particularly in Southeast Asia, where qualification testing tends to be delegated to schoolteachers. The enthusiasm and experience of participants alone was not enough to enable accurate classification. Without detailed training in formal assessment requirements, the credibility of school-based qualifications cannot be assured. Participation in structured assessment protocols, as seen in one participant, may offer another pathway for strengthening teacher capacity to judge cognitive demand (Gilmore, 2001).
Abbreviations
| HOTS | Higher-order thinking skills |
| LOTS | Lower-order thinking skills |
| MCQ | Multiple-choice questions |
| OIB | Ordered item booklet |
| RBT | Revised Bloomâs taxonomy |
| SOLO | Structure of the Observed Learning Outcome |
Acknowledgements
The authors would like to express their sincere appreciation to the participating teachers for their time, effort, and valuable insights throughout the study. Their willingness to engage in professional learning and to share their experiences meaningfully enriched the research.
Data Availability Statement
The data supporting the findings of this study are openly accessible in University of Auckland Figshare (Version 6) at https://doi.org/10.17608/k6.auckland.23691501.
Funding
This research was supported by the Ministry of Education, Malaysia.
Ethical Consideration
Approval to conduct this study was granted by the University of Auckland Human Participants Ethics Committee (Reference: UAHPEC25328). Data collection was carried out with the necessary consent and clearance from participating institutions and individuals. All school and participant names mentioned in the study are pseudonyms or anonymized.
About the Authors
Dayana Sirri is a postgraduate student at the University of Auckland, affiliated with the Faculty of Arts and Education, School of Learning, Development, and Professional Practice. She is also a secondary school science teacher in Malaysia. Her research interests include science education, teacher assessment literacy, and the development of higher-order thinking skills through classroom-based assessment practices in the Malaysian education context.
Gavin T. L. Brown is a psychometrician and cross-cultural psychologist of assessment. His research focuses on the assessment of student achievement and learning outcomes, particularly in the areas of test design, administration, scoring, and feedback. He has held academic positions at the University of Auckland (since 2005) and the Hong Kong Institute of Education (2009â2011) and currently holds honorary appointments at the Education University of Hong Kong, UmeÃ¥ University (Sweden), and Thammasat University (Thailand). Prior to his academic career, he was a secondary school teacher in New Zealand and worked in test development at NZCER and Auckland UniServices.
Amanda Harper is a senior tutor in the Faculty of Science at the University of Auckland, specializing in biological sciences. She contributes to science education through curriculum development, laboratory instruction, and pedagogical research aimed at enhancing teaching and learning in the tertiary science education context.
References
Abdul Aziz, N. A. (2022). Socratic method and SOLO taxonomy as assessment instruments during COVID-19 pandemic. In S. A. Abdul Karim & S. A. Husain (Eds.), Engineering and sciences teaching and learning activities: New systems throughout COVID-19 pandemics (Vol. 381, pp. 71â81). Springer International Publishing. https://doi.org/10.1007/978-3-030-79614-3.
Abu Hassan, F. N., Mohamad, Q. ʾAqilah, Mohd Rosli, N. A., Ajmain@Jimaʾain, M. T., & Yusof Azuddin, S. K. (2020). The implementation of higher order thinking skills (HOTS) in Malaysian secondary schools: Post PISA 2009. International Journal of Psychosocial Rehabilitation, 24(5), 5510â5517. https://doi.org/10.37200/ijpr/v24i5/pr2020258.
Adams, N. E. (2015). Bloomâs taxonomy of cognitive learning objectives. Journal of the Medical Library Association, 103(3), 152â153. https://doi.org/10.3163/1536-5050.103.3.010.
Aisyah, A., Salehuddin, K., & Aman, I. (2019). Eliciting elements of higher order thinking skills in the higher secondary examination question structure in Japan and Malaysia. Proceedings of the Regional Conference on Science, Technology and Social Sciences (RCSTSS 2016), (pp. 455â464) Springer. https://doi.org/10.1007/978-981-13-0203-9.
Anderson, L. W., & Krathwohl, D. R. (2001). A taxonomy for learning, teaching, and assessing: A revision of Bloomâs taxonomy of educational objectives. Longman.
BERNAMA. (2020, April 15). UPSR dan PT3 bagi tahun 2020 dibatalkan [UPSR and PT3 for the year 2020 cancelled]. BERNAMA. https://www.bernama.com/bm/news.php?id=1832182.
Biggs, J. B., & Collis, K. F. (1982). Evaluating the quality of learning: The SOLO taxonomy (Structure of the Observed Learning Outcomes). Academic Press Inc. https://doi.org/10.1016/C2013-0-10375-3.
Biggs, J. B., & Collis, K. F. (1989). Towards a model of school-based curriculum development and assessment using the SOLO taxonomy. Australian Journal of Education, 33(2), 151â163. https://doi.org/10.1177/168781408903300205.
Biggs, J., & Tang, C. (2011). Designing constructively aligned outcomes-based teaching and learning. In Teaching for quality learning at university (4th ed., pp. 111â278). Open University Press. http://ebookcentral.proquest.com/lib/auckland/detail.action?docID=798265.
Bloom, B. S., Engelhart, M. D., Furst, E. J., Hill, W. H., & Krathwohl, D. R. (1956). Taxonomy of educational objectives: The classification of educational goals. David McKay Company, Inc. https://doi.org/10.1300/J104v03n01_03.
Boulton-Lewis, G. M. (1995). The SOLO taxonomy as a means of shaping and assessing learning in higher education. Higher Education Research & Development, 14(2), 143â154. https://doi.org/10.1080/0729436950140201.
Brookhart, S. M. (2010). General principles for assessing higher-order thinking. In How to assess higher-order thinking skills in your classroom (pp. 17â38). ASCD Publications.
Campbell, I. (2007). Chi-squared and FisherâIrwin tests of two-by-two tables with small sample recommendations. Statistics in Medicine, 26(19), 3661â3675. https://doi.org/10.1002/sim.2832.
Caridade, C. M. R., & Pereira, V. (2023). SOLO taxonomy to assessment of skills and competencies required to students: Comparison between online versus face-to-face exam. In A. Mesquita, A. Abreu, C. V. João, C. Santana, & C. H. P. de Mello (Eds.), Perspectives and trends in education and technology (pp. 565â574). Springer.
Chan, C. C., Tsui, M. S., Chan, M. Y. C., & Hong, J. H. (2002). Applying the Structure of the Observed Learning Outcomes (SOLO) taxonomy to studentsâ learning outcomes: An empirical study. Assessment and Evaluation in Higher Education, 27(6), 511â527. https://doi.org/10.1080/0260293022000020282.
Cicchetti, D. V., & Feinstein, A. R. (1990). High agreement but low kappa: II. Resolving the paradoxes. Journal of Clinical Epidemiology, 43(6), 551â558. https://doi.org/10.1016/0895-4356(90)90158-L.
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1), 37â46.
Collis, K. F., & Davey, H. A. (1986). A technique for evaluating skills in high school science. Journal of Research in Science Teaching, 23(7), 651â663.
Crowe, A., Dirks, C., & Wenderoth, M. P. (2008). Biology in Bloom: Implementing Bloomâs taxonomy to enhance student learning in biology. CBE Life Sciences Education, 7, 368â381. https://doi.org/10.1187/cbe.08-05-0024.
Elmas, R., Rusek, M., Lindell, A., Nieminen, P., Kasapoǧlu, K., & BÃlek, M. (2020). The intellectual demands of the intended chemistry curriculum in Czechia, Finland, and Turkey: A comparative analysis based on the revised Bloomâs taxonomy. Chemistry Education Research and Practice, 21(3), 839â851. https://doi.org/10.1039/d0rp00058b.
Engelhard Jr., G. (2011). Evaluating the bookmark judgments of standard-setting panelists. Educational and Psychological Measurement, 71(6), 909â924. https://doi.org/10.1177/0013164410395934.
Gani, M. S. H., & Abdullah, S. K. (2011). Test item analysis: An educator professionalism approach. US-China Education Review, 3, 307â322.
Geisinger, K. F., & McCormick, C. M. (2010). Adopting cut scores: Post-standard-setting panel considerations for decision makers. Educational Measurement: Issues and Practice, 29(1), 38â44. https://doi.org/10.1111/j.1745-3992.2009.00168.x.
Gillies, R. M. (2020). The Structure of Observed Learning Outcomes (SOLO) taxonomy: Assessing studentsâ reasoning, problem solving, and learning. In Inquiry-Based Science Education (pp. 93â101). CRC Press. http://ebookcentral.proquest.com/lib/auckland/detail.action?docID=6028810.
Gilmore, A. (2001). The NEMP experience: Professional development of teachers through the national education monitoring project. New Zealand Annual Review of Education, 10, 141â166.
Hassan, M. N., Mustapha, R., Nik Yusuff, N. A., & Mansor, R. (2017). Development of higher order thinking skills module in science primary school: Needs analysis. International Journal of Academic Research in Business and Social Sciences, 7(2), 624â628.
Hattie, J., Biggs, J., & Purdie, N. (1996). Effects of learning skills interventions on student learning: A meta-analysis. Review of Educational Research, 66(2), 99â136. https://doi.org/10.3102/00346543066002099.
Hattie, J., & Brown, G. T. L. (2004). Cognitive processes in asTTle: The SOLO taxonomy. (Technical report). University of Auckland. http://tinyurl.com/j2epdkq.
Hattie, J., & Purdie, N. (1998). The SOLO model: Addressing fundamental measurement issues. In B. Dart & G. Boulton-Lewis (Eds.), Teaching and Learning in Higher Education (pp. 145â176). ACER Press.
Holmes, K. (2005). Analysis of asynchronous online discussion using the SOLO taxonomy. Australian Journal of Educational and Developmental Psychology, 5, 117â127.
Howell, D. C. (2011). Chi-Square Test â Analysis of contingency tables. In M. Lovric (Eds.), International Encyclopedia of Statistical Science. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-04898-2_174.
Husin, A. S. A. (2020). Case study of difficulty index and discrimination index item of Year 5 English language summative test (comprehension). Sains Humanika, 12(2â2), 57â66. https://doi.org/10.11113/sh.v12n2-2.1786.
Ibrahim Badr, S. K. (2020). SOLO taxonomy in a visible learning school: A quasi-experimental design to study the effect of SOLO taxonomy on student metacognitive ability; SOLO taxonomy as a framework of designing comprehension strategies. Unpublished dissertation, The British University.
Idek, M. S. (2016). Q-matrix as a method in promoting student-generated questions to develop critical thinking skills. Journal on Technical and Vocational Education, 1(1), 30â37. https://www.researchgate.net/publication/304675128.
Idek, M. S. (2020). Fostering ESL critical reading skills through SOLO taxonomy [Masterâs thesis, Universiti Teknologi MARA]. ResearchGate. https://www.researchgate.net/publication/344138208.
Irvine, J. (2021). Taxonomies in education: Overview, comparison, and future directions. Journal of Education and Development, 5(2), 1â25. https://doi.org/10.20849/jed.v5i2.898.
Jamalludin, N. H., & Zamzuri, Z. H. (2018). Penilaian Taksonomi Bloom ke atas Peperiksaan Menggunakan Pendekatan Pembuatan Keputusan Multikriterium (Assessing Bloomâs Taxonomy on Examination Papers Using Multicriteria Decision Making Approach). Journal of Quality Measurement and Analysis, 14(1), 115â123.
Kang, S. C. (2014, March 23). PT3 to replace PMR. The Star. https://www.thestar.com.my/news/education/2014/03/23/pt3-to-replace-pmr.
Karantonis, A., & Sireci, S. G. (2006). The bookmark standard-setting method: A literature review. Educational Measurement: Issues and Practice, 25(1), 4â12. https://doi.org/10.1111/j.1745-3992.2006.00047.x.
Kim, M. K., Patel, R. A., Uchizono, J. A., & Beck, L. (2012). Incorporation of Bloomâs taxonomy into multiple-choice examination questions for a pharmacotherapeutics course. American Journal of Pharmaceutical Education, 76(6), 1â8. https://doi.org/10.5688/ajpe766114.
Koh, K. H. (2011). Improving teachersâ assessment literacy through professional development. Teaching Education, 22(3), 255â276. https://doi.org/10.1080/10476210.2011.593164.
Krathwohl, D. R. (2002). A revision of Bloomâs taxonomy: An overview. Theory into Practice, 41(4), 212â218.
Larsen, T. M., Endo, B. H., Yee, A. T., Do, T., & Lo, S. M. (2022). Probing internal assumptions of the revised Bloomâs taxonomy. CBE Life Sciences Education, 21(4), 1â12. https://doi.org/https://doi.org/10.1187/cbe.20-08-0170.
Lee, Y. J., Kim, M., & Yoon, H. G. (2015). The intellectual demands of the intended primary science curriculum in Korea and Singapore: An analysis based on revised Bloomâs taxonomy. International Journal of Science Education, 37(13), 2193â2213. https://doi.org/10.1080/09500693.2015.1072290.
Lee, Y.-J., Kim, M., Jin, Q., Yoon, H.-G., & Matsubara, K. (2017). East-Asian primary science curricula: An overview using Revised Bloomâs Taxonomy. Springer. https://doi.org/10.1080/02188791.2019.1585053.
Lembaga Peperiksaan. (2013). Penilaian Menengah Rendah 2013: Sains Kertas 1 [Lower Secondary Assessment 2013: Science Paper 1]. https://viewnow.myschoolchildren.com/tag/science-paper-1-pmr-2013/.
Lembaga Peperiksaan. (2019a). Penilaian Tingkatan 3 2019: Sains Kertas 1 [Form 3 Assessment 2019: Science Paper 1]. https://bumigemilang.com/sains-pt3-tingkatan-3-soalan-peperiksaan-percubaan-ujian-nota/.
Lembaga Peperiksaan. (2019b). Soalan-soalan lazim pemerkasaan pentaksiran tingkatan 3 (PT3) di sekolah mulai tahun 2020 [Frequently Asked Questions on the Strengthening of Form 3 Assessment (PT3) in Schools from 2020]. https://lp.moe.gov.my/images/bahan/pt3/2019/Soalan%20FAQ%20Pemerkasaan%20PT3_9%20MEI%202019.pdf.
Lembaga Peperiksaan. (2023). Panduan pembinaan item kemahiran berfikir aras tinggi [Guide to Developing Higher-Order Thinking Skills Items]. Kementerian Pendidikan Malaysia.
Lemons, P. P., & Lemons, J. D. (2013). Questions for assessing higher-order cognitive skills: Itâs not just Bloomâs. CBE Life Sciences Education, 12, 47â58. https://doi.org/10.1187/cbe.12-03-0024.
Lim, H. L., & Wun, T. Y. (2011). Developing pre-algebraic thinking in generalizing repeating patterns using the SOLO model. US-China Education Review, 6, 774â780.
Lim, H. L., Wun, T. Y., & Idris, N. (2010). Super-item test as an alternative assessment tool. Journal International: Malaysia, 1â15.
Lucander, H., Bondemark, L., Brown, G., & Knutsson, K. (2010). The structure of observed learning outcome (SOLO) taxonomy: A model to promote dental studentsâ learning. European Journal of Dental Education, 14(3), 145â150. https://doi.org/10.1111/j.1600-0579.2009.00607.x.
Marzano, R. J., & Kendall, J. S. (2007). The new taxonomy of educational objectives. Corwin Press.
McHugh, M. L. (2012). Interrater reliability: The kappa statistic. Biochemica Medica, 22(3), 276â282. https://hrcak.srce.hr/89395.
Mitzel, H. C., Lewis, D. M., & Green, D. R. (2001). The bookmark procedure: Psychological perspectives. In G. J. Cizek (Ed.), Setting performance standards: Concepts, methods, and perspectives (pp. 249â281). Lawrence Erlbaum Associates, Inc.
MOE. (2013). Malaysia Education Blueprint 2013â2025. Ministry of Education Malaysia. http://www.moe.gov.my.
MOE. (2016). Buku Penerangan KSSM (KSSM Information Book). Ministry of Education Malaysia. http://www.moe.gov.my.
MOE. (2017). Sains â Dokumen Standard Kurikulum dan Pentaksiran Tingkatan 3 (Science â Standard Curriculum and Assessment Document) Form 3. Ministry of Education Malaysia. http://www.moe.gov.my.
MOE. (2021). Format Instrumen Pentaksiran Dan Pelaporan Ujian Akhir Sesi Akademik Sekolah Menengah Tingkatan 1, 2 dan 3 (Assessment and Reporting Instrument Format for Final Examinations in Academic Session for Secondary School Form 1, 2, and 3). Ministry of Education Malaysia.
Mohamed, O. J., Zakar, N. A., & Alshaikhdeeb, B. (2019). A combination method of syntactic and semantic approaches for classifying examination questions into Bloomâs taxonomy cognitive levels. Journal of Engineering Science and Technology, 14(2), 935â950.
Mohd Nor, N., & Idris, N. (2010). Assessing studentsâ informal inferential reasoning using a SOLO taxonomy-based framework. Procedia â Social and Behavioral Sciences, 2(2), 4805â4809. https://doi.org/10.1016/j.sbspro.2010.03.774.
Motlhabane, A. (2017). Unpacking the South African physics examination questions according to Bloomâs revised taxonomy. Journal of Baltic Science Education, 16(6), 919â931.
Omar, N., Haris, S. S., Hassan, R., Arshad, H., Rahmat, M., Zainal, N. F. A., & Zulkifli, R. (2012). Automated analysis of exam questions according to Bloomâs taxonomy. Procedia â Social and Behavioral Sciences, 59(2012), 297â303. https://doi.org/10.1016/j.sbspro.2012.09.278.
Pegg, J., & Tall, D. (2005). The fundamental cycle of concept construction underlying various theoretical frameworks. Zentralblatt für Didaktik der Mathematik, 37(6), 468â475. https://doi.org/10.1007/BF02655855.
Perez, E. V., Santos, L. M. R., Perez, M. J. V., De Castro Fernandez, J. P., & Martin, R. G. (2012). Automatic Classification of Question Difficulty Level: Teachersâ Estimation vs. Studentsâ Perception. Proceedings â Frontiers in Education Conference, FIE. https://doi.org/10.1109/FIE.2012.6462398.
Phillips, A. W., Smith, S. G., & Straus, C. M. (2013). Driving deeper learning by assessment: An adaptation of the revised Bloomâs taxonomy for medical imaging in gross anatomy. Academic Radiology, 20(6), 784â789. https://doi.org/10.1016/j.acra.2013.02.001.
Piaget, J. (1950). The psychology of intelligence. Routledge.
Prakash, E. S., Narayan, K. A., & Sethuraman, K. R. (2010). Student perceptions regarding the usefulness of explicit discussion of âStructure of the Observed Learning Outcomeâ taxonomy. Adv Physiol Educ, 34, 145â149. https://doi.org/10.1152/advan.00026.2010.-One.
Richardson, V. (1998). How teachers change. Focus on basics, 2, 1. https://www.researchgate.net/publication/285898937.
Sangodiah, A., Ahmad, R., & Wan Ahmad, W. F. (2014). A review of feature extraction approaches in question classification using support vector machines. Proceedings â 4th IEEE International Conference on Control System, Computing and Engineering, ICCSCE 2014, November, 536â541. https://doi.org/10.1109/ICCSCE.2014.7072776.
Singh, R. K. V., & Shaari, A. H. (2019). The Analysis of Higher-Order Thinking Skills in English Reading Comprehension Tests in Malaysia. Malaysian Journal of Society and Space, 1, 12â26. https://doi.org/10.17576/geo-2019-1501-02.
Sirri, D. (2025). Ordered item booklet (Version 6) [Data set]. University of Auckland Figshare. https://doi.org/10.17608/k6.auckland.23691501.
Stemler, S. E. (2004). A comparison of consensus, consistency, and measurement approaches to estimating interrater reliability. Practical Assessment, Research and Evaluation, 9(4).
Tan, H. L. (2006). Motivation and Task Difficulty: A SOLO Experience with Adult Learners. Jurnal Pendidikan, 31, 71â81.
Tee, T. K., Md Yunos, J., Hassan, R., Yee, M. H., Hussein, A. H., & Mohamad, M. M. (2012). Thinking Skills for Secondary School Students in Malaysia. Policy & Practice of Teachers & Teacher Education, 2(2), 12â23.
Thompson, T. (2008). Mathematics Teachersâ Interpretation of Higher-Order Thinking in Bloomâs Taxonomy. International Electronic Journal of Mathematics Education, 3(2), 96â109. http://www.iejme.com/022008/d2.pdf.
Trapsilasiwi, D., Murtikusuma, R. P., Pambudi, D. S., Oktavianingtyas, E., & Fauziyah, M. E. (2020). Studentsâ mathematical representation at Hatyaiwittayalaisomboonkulkanya School, Thailand, based on SOLO taxonomy in solving PISA problems. Journal of Physics: Conference Series, 1490(1), 1â11. https://doi.org/10.1088/1742-6596/1490/1/012005.
Weay, A. L., Masood, M., & Abdullah, S. H. (2016). Systematic review of revised Bloom taxonomy, SOLO taxonomy and Webbâs depth of knowledge (DOK) in assessing studentsâ historical understanding in learning history. Malaysian Journal of Higher Order Thinking Skills in Education. https://doi.org/10.13140/RG.2.2.30423.47526.
Webb, N. L. (1997). Criteria for alignment of expectations and assessments in mathematics and science education (Research Monograph No. 6). Wisconsin Center for Education Research, University of WisconsinâMadison.
Webb, N. L. (1999). Alignment of science and mathematics standards and assessments in four states (Research Monograph No. 18). Wisconsin Center for Education Research, University of WisconsinâMadison.
Wei, B., & Ou, Y. (2019). A comparative analysis of junior high school science curriculum standards in Mainland China, Taiwan, Hong Kong, and Macao: Based on revised Bloomâs taxonomy. International Journal of Science and Mathematics Education, 17(8), 1459â1474. https://doi.org/10.1007/s10763-018-9935-6.
Xu, Y., & Brown, G. T. L. (2016). Teacher assessment literacy in practice: A reconceptualization. Teaching and Teacher Education, 58, 149â162. https://doi.org/10.1016/j.tate.2016.05.010.
Zaiful Shah, N. F. A., & Zakaria, Z. (2024). The integration of higher order thinking skills in science classrooms: Malaysian teachersâ perspectives and practice. International Journal of Academic Research in Progressive Education and Development, 13(2), 570â586. https://doi.org/10.6007/ijarped/v13-i2/21306.
Zapf, A., Castell, S., Morawietz, L., & Karch, A. (2016). Measuring inter-rater reliability for nominal data: Which coefficients and confidence intervals are appropriate? BMC Medical Research Methodology, 16(93), 1â10. https://doi.org/10.1186/s12874-016-0200-9.
Zulkifli, F., & Abidin, R. Z. (2022). A revised Bloomâs taxonomy: An essential approach to constructing assessment questions for the probability and statistics course. International Journal of Academic Research in Business and Social Sciences, 12(3), 588â602. https://doi.org/10.6007/ijarbss/v12-i3/13001.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}