Abstract
In niche markets such as the European legume market, transparency is crucial to promote competitive conditions and enable informed decisions. The LeguDash dashboard aims to increase the transparency of the legume market through a publicly accessible and interactive information platform thereby facilitating legume cultivation and increasing sustainability in cropping systems. Guideline-based qualitative interviews with selected experts were conducted to discuss financing and sponsorship models. The interviews were subjected to qualitative content analysis, both manually and using a Large Language Model (LLM)-based methodology. ChatGPT was used for the LLM-supported analysis. As a result of the interviews, various financing and sponsorship models were proposed, including public funding, subscription-based paid content with a paywall and a model where companies provide data in exchange for free access. Flexible, customizable solutions that can be integrated into existing systems are required. Methodologically, the LLM-supported content analysis of the qualitative data material provided valuable, partly inconsistent and partly corrective, insights. These insights can be used to fine-tune manual analysis characterized by specialist context knowledge beyond the immediate interview content. LLM-enriched manual analysis can potentially enable a deeper and more contextually appropriate analysis of the qualitative data. Therefore, LLM-assisted analyses of qualitative interviews seem promising to complement manual qualitative research for agribusinesses.
1. Introduction
Market transparency is essential for efficient and competitive markets, particularly in the European legume sector, where specialized products and limited trading volumes create challenges in pricing and supply dynamics. Transparent markets reduce information asymmetries, promote trust and enable stakeholders, including farmers, traders, processors and policy makers, to make informed decisions based on reliable data (Klug and Prinz, 2023). By providing access to critical information such as pricing developments and supply-demand trends, transparency improves resource allocation, reduces price volatility, and encourages market participation (Kim et al., 2024; Kizito, 2019). The fragmentation of supply chains and existing bottlenecks in resources and cooperation make data consistency and transparency considerably more difficult, which is particularly noticeable in the legume market (Mardenli et al., 2023). Transparent markets play a crucial role in promoting fairness, resilience and sustainability in agricultural systems (Klug and Prinz, 2023).
The data in the legume sector is often not freely accessible and rarely analyzed, which makes market transparency difficult. For example, the H2020 LegValue project highlights that organic value chains in particular are difficult to analyze due to insufficient data collection and availability (Smadja and Muel, 2021). The existing data is not fundamentally of poor quality. The problem is rather that it is often scattered, unstructured and not available over long periods of time. As a result, a lot of useful information is difficult to collate and utilize. LeguDash addresses this issue by integrating existing data sources, such as data from the Agricultural Market Information Company (AMI), Federal Statistical Office of Germany (Destatis), and European Statistical Office (Eurostat), which provide crucial market insights and contribute to a clearer understanding of market dynamics. By disclosing the origin of the data and highlighting existing gaps, the dashboard enables a better founded and more reliable assessment of the market situation. As Kshetri (2018) emphasizes, the traceability of data origins is crucial in making digital information systems effective and trustworthy.
However, the project currently faces a significant challenge in identifying a viable financing model for long-term operation of LeguDash. As highlighted by Köpp et al. (2024), the absence of sustainable funding threatens the platform’s ability to fulfill its potential as a transformative tool for market transparency and stakeholder engagement. Ensuring the long-term viability of LeguDash will require innovative financing strategies that balance accessibility, stakeholder engagement, and financial stability. In order to identify suitable financing and sponsorship models for LeguDash, qualitative expert interviews were conducted with potential financing and sponsorship institutions. In addition to the substantive issues of market transparency and sustainable sponsorship models, the study also attempts to address a methodological research gap. The potential of LLMs for analyzing qualitative and heterogeneous data material from expert interviews will be investigated.
2. Background
2.1 Sponsorship of digital platforms
Digital dashboards offer a practical solution for enhancing the efficiency of market structures without distorting prices (Overgaard et al., 2008). These tools consolidate and present data in an accessible format, allowing stakeholders to monitor market trends and make evidence-based decisions. Interactive and automatically updated platforms are especially promising, as they not only improve the user experience but also ensure that the data remains up-to-date and reliable (Klievink et al., 2016). However, the successful implementation of such platforms requires neutral sponsorships to foster trust. Neutral funding sources reduce perceived biases, ensuring stakeholders view the information as credible and impartial. Despite these advantages, establishing sustainable financing and sponsorship models for such dashboards remains a significant challenge. Long-term funding strategies are essential to ensure that these platforms remain operational and evolve in response to changing market demands. Tollens (2006) underscores this as a recurring issue in market information systems, which often struggle with financial sustainability beyond their initial development phase.
Market information systems are generally categorized as stand-alone, integrated, or self-organizing platforms (Singh et al., 2023). Each of these configurations addresses specific stakeholder needs and aims to balance inclusivity with financial feasibility. Stand-alone platforms function independently, often relying on single-source funding. Integrated systems merge with existing structures to pool resources, while self-organizing platforms leverage decentralized contributions from users or other stakeholders. The ability to align stakeholder needs with sustainable funding mechanisms is critical for these systems to succeed (Kizito, 2019). In the legume market, the LeguDash dashboard has been developed as a tool to enhance transparency and improve market efficiency. By offering a publicly accessible, interactive platform that gathers relevant data on legumes such as yield and area of arable land as well as price trends and predictions, LeguDash aims to address the unique challenges of the German legume market, including its fragmented supply chain and lack of reliable market data (Köpp et al., 2025).
When farmers have access to reliable market data, cultivation becomes easier to plan (Overgaard et al., 2008). Legumes offer numerous environmental benefits by fixing nitrogen from the air, reducing the need for synthetic fertilizers (Luo et al., 2024) and thus reducing greenhouse gas emissions (Jensen et al., 2012). They improve soil fertility and reduce the risk of erosion and the need for tillage (Poeplau et al., 2011). They also promote biodiversity by creating habitats for pollinators and diversifying crop rotations (Stagnari et al., 2017), while reducing dependence on chemical pesticides. In this way, they make a significant contribution to more sustainable agricultural systems.
2.2 Dashboard for legumes (LeguDash)
LeguDash was developed at the South Westphalia University of Applied Sciences (FH SWF) as a prototype for a digital dashboard specifically for the German legume market funded by the Federal Ministry of Food and Agriculture of Germany (BMEL) as part of a strategy to promote protein plant cultivation. This strategy includes a network of stakeholders for promoting legumes called LeguNet. Based on qualitative surveys, key problems in the area of market transparency were identified and transferred to the design of the dashboard. LeguDash offers a publicly accessible, interactive web platform that visualises relevant market data on legumes - such as acreage, import and export volumes (Destatis, and Eurostat), price information (AMI), and price predictions (based on stock future prices on wheat and soybean meal of the Chicago Board of Trade). The prototype was based on the Python framework Django, supported by SQLite for data storage, BeautifulSoup and Selenium for web scraping, Plotly for visualization and Bootstrap for a user-friendly presentation in the browser. The platform is aimed in particular at farmers, traders, processors and breeders in Germany and serves as a tool for better assessment of market conditions and price developments by gathering data from different sources that are less intuitive for end users to work with such as Destatis. Special price indicators, developed by the Department of Agriculture at FH SWF, supplement the market information. These indicators are based on historical data, a regression analysis and feed value exchanges of wheat and soybean meal according to Löhr’s method (Löhr, 1977). Although they do not replace actual price quotations, they provide a sound basis for planning and risk management along the value chain. The aim is to promote market transparency by encouraging price data exchange throughout the German legume market to strengthen the bargaining position of stakeholders and facilitate easier access to sales opportunities (Köpp et al., 2024). LeguDash is available online at https://legudash.digitalfarmlab.fh-swf.de/.
2.3 LLMs for qualitative content analysis
LLMs are increasingly used as tools for analyzing qualitative interviews, providing capabilities to enhance the efficiency and accuracy of thematic data analysis (Hayes, 2025). LLMs are designed to process large volumes of unstructured text, which aligns well with the requirements of qualitative research where coding and pattern recognition are fundamental. These models assist in identifying recurring themes, patterns, and relationships in textual data, achieving matching rates that are often comparable to human coders in specific applications (Chew et al., 2023). The use of LLMs in qualitative analysis is particularly advantageous for handling extensive datasets. LLMs enable rapid thematic analysis by automating the identification of central themes and sub-themes, which can streamline the initial stages of qualitative content analysis (Rasheed et al., 2024). These capabilities are further supported by advancements in frameworks that enhance the scalability and efficiency of LLM-based approaches. For instance, integrating LLMs with coding software and automated analysis tools facilitates systematic workflows and reproducibility in research processes.
Despite their advantages, challenges arise in the application of LLMs for qualitative content analysis. Biases embedded in the training data of these models can affect their outputs, potentially leading to inaccurate or incomplete interpretations (Ashwin et al., 2023). Biases can manifest as overgeneralization, a lack of nuanced insights, or the prioritization of dominant themes while neglecting less prominent but relevant details. These limitations underscore the importance of understanding the operational characteristics of LLMs in qualitative research settings as well as the creation of well-formulated prompts. In their current state, LLMs provide structured outputs that are useful for identifying key themes and patterns within qualitative data. They serve as tools to process and organize large datasets efficiently, providing a foundation for more detailed analyses. Their application has been particularly noted in exploratory studies and large-scale projects requiring rapid processing, enabling researchers to extract meaningful patterns and structure from unstructured text data (De Paoli, 2023).
3. Material and methods
3.1 Interviews
As part of this study, seven expert interviews were conducted via the video conferencing tool Zoom between March and July of 2024, where the first interview was conducted with two experts at once. The experts were selected according to the criteria of importance within the value chain, in-depth specialist knowledge and professional experience and can be assigned to the areas of trade, processing and interest groups. Table 1 describes the interviewees and their characteristics in anonymized form. Possible conflicts of interest and their potential impact on interview statements are also included. The audio recordings lasted approximately one hour each and were transcribed using the f4x audio transcription program. The analyses were conducted in accordance with the ethical principles of the Declaration of Helsinki. According to the German legislation in force at the time of data collection, the relevant research guidelines and the regulations of our university, a review by an ethics committee was not required. This is due to the fact that participation in the study did not endanger or impair the respondents. All participants were comprehensively informed about the aim and procedure of the study, including the use, processing and storage of their data. It was ensured that the legal framework was complied with and that the anonymity of the participants was guaranteed, e.g. obfuscation of sensitive information such as real names. The results will also be shared with interviewees once the analyses are completed and published. Their informed consent was obtained prior to participation.

Main characteristics of the interviewees
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
3.2 Code schema development
After the presentation of the LeguDash prototype, the interviews focused on identifying relevant aspects of the dashboard for potential sponsoring institutions and how a possible funding model could be designed (cf. Table 2). Before analyzing the expert interviews, a qualitative content analysis with deductive category assignment was planned, following the approach of Mayring (Mayring, 2010: p. 602). This method structures the material into analyzable categories that are defined in advance. A coding scheme was developed prior to the analysis, which included nominal categories based on relevant literature, clear coding rules, and coding examples (cf. Table 3). During the coding of the first transcripts, the possibility to revise and adapt the coding scheme was considered essential, as new categories emerged that had not been previously anticipated. Once the coding scheme was finalized, all transcripts were coded accordingly. The transparency and reproducibility of the coding process were ensured by the precise definition of categories and the inclusion of example passages (Mayring, 2010: p. 602; Mayring and Fenzl, 2019: p. 638).
Most important questions from the interview guide
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
Overview of codes and their definitions.
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
For example, a code was assigned for statements on funding if the interviewees commented on potential donors, strategies for acquiring funds or funding security. The same coding scheme was also applied to the LLM-supported analysis in order to ensure consistent and comparable evaluation of the content.
3.3 Coding assessment
The transcripts were analyzed both manually and using the GPT-4o model gpt-4o-2024-11-20. The LLM-based process was repeated ten times to investigate whether the LLMs produced fluctuating results. This method aimed to evaluate the potential of LLMs to improve content analysis and to test the extent to which the time-consuming manual coding process can be replaced by LLM-based automation. The focus here is on how different approaches influence the identification of focal points and topics in the interviews. The aim was not only to test the efficiency of LLM-supported analysis, but also to find out to what extent it can provide deeper insights and more differentiated results that reflect the specific context of the expert interviews. Particularly, the feasibility of using fully automatic qualitative evaluation of automatically transcribed interview datasets is of interest because it involves a niche topic, heterogeneous interview partners, and natural speech patterns that encompass many filler words and grammatically incomplete as well as occasionally not-fully coherent sentences. As a consequence, coding these interviews is challenging even for human coders. Table 4 shows the method for fine-grained prompting GPT for coding, following the best practice recommendations of Dunivin (2025) such as role assignment, code definition, one code per task, justification and structured output. GPT queries were implemented using the package LlamaIndex in Python 3.10. Briefly, sentences of each interview were enumerated by prepending a number in square brackets to the text which aims to allow unambiguous assignment of codes to sentences. For each interview, an index was built using a VectorStoreIndex and the embedding model text-embedding-3-large of OpenAI. Each index was independently queried ten times for each code by using the GPT-4o model. Default model and embedding parameters were used to allow for some variation in the output that might better reflect real world applications. Output codes were converted to JSON-format by the structured output API of LlamaIndex which contains the indices of the referenced sentences and the justification for each code. Result statistics were gathered and visualized using the Python packages pandas, matplotlib and seaborn. To assess the agreement within GPT coding and between GPT and manual coding, Krippendorff’s coefficient (α) and observed agreement (ao) was calculated based on the assigned codes for each sentence using the nltk Python package in two ways: (1) by considering all sentences and assuming non-coded sentences are deliberate and (2) by only focusing on coded sentences. For the comparison of the LLM based coding against the manual coding, we further aggregated the ten repetitions of the LLM coding to majority consensus codes, e.g. sentences are assigned a code if and only if the code assignment is present in at least five repetitions.
4. Results and discussion
4.1 Interview summaries
The following summaries are based on manual deduction and interpretation. The interviews show that companies are interested in flexible and adaptable solutions that meet their specific requirements and increase efficiency. These solutions could enable different sponsoring institutions to use selected views and functions according to their individual needs. The discussion on the funding of the LeguDash dashboard brought up public funding as a central approach to ensure the greatest possible accessibility and to promote market transparency as a public good. In contrast, one interviewee suggested paid-use models, such as paywalls or subscriptions, aim for a market-oriented cost structure and sustainable funding. Another model, based on data generation by so-called reporting agent, combines the provision of data with free access to the dashboard, creating mutual benefits. These funding models reflect different ways of ensuring the long-term financial sustainability and functionality of the dashboard. Interestingly, two interviews did not further discuss funding opportunities at all.
Each model requires specific prerequisites: the public financing model requires strong political support and involvement of relevant stakeholders, the market-based model requires an analysis of the willingness of potential users to pay and a convincing business model, and the reporting unit concept requires an efficient infrastructure for data collection and processing as well as incentives for continuous data collection. Companies interested in hosting the LeguDash dashboard as a sponsoring institution could adopt a flexible funding model that balances public access with potential subscription-based features.
The emphasis on modular customization allows users to adapt the dashboard to their specific needs and thus increase its relevance. Seamless integration with existing systems is essential for ease of use. Regular monitoring and updates are crucial to ensure the reliability of the service and keep the system up to date. To ensure the long-term financial sustainability and success of the dashboard, specific measures need to be taken for each proposed funding model. Particular emphasis is placed on the importance of implementation, which is identified as a key challenge.
The number and distribution of codes clearly indicate that experts considered the practical hurdles of project implementation more relevant than funding concerns. The frequency of codes underlines that the possible challenges in the implementation of the dashboard are a major concern. This is described in more detail in Figure 1c. However, most parts, derived from the coded sections, of the interviews were discussions on the data and data quality of legumes on the market. One major aspect emerged during an interview that companies prefer flexible solutions, and suggested to develop a replica of the dashboard that contains the same information. This replica should be tailored to a company’s specific software. This emphasizes the need for adaptability, compatibility and flexibility. The replica should retain the same control options and functions as well as the visual representations. However, adapting to the programming specifications of other institutions proved to be challenging in some cases. One interviewed party, which is part of a public institution, has also started to transfer the content into its own structures and is working on reprogramming it accordingly to ensure full integration. Another request was the ability to customize individual visualizations and forecasting models without having to take over the entire dashboard, which underlines the importance of flexibility and selective use. Another relevant aspect is compatibility with the companies’ existing systems so that integration can run as smoothly as possible. In the context of adapting the dashboard, for example, the provision of information sources and possible visual presentations of the different data sets are important.
4.2 Evaluation of LLM-based coding
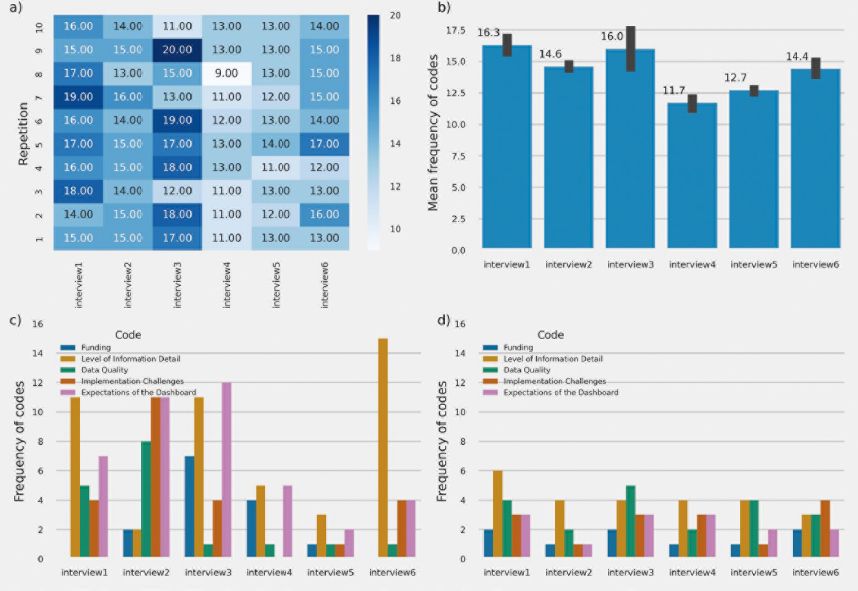
Reliability: With respect to content analysis with LLMs, our first aim was to check the reliability of using GPT-4o as a coding agent. For this reason, we independently repeated coding queries ten times for each interview. Figure 1a, b, and d show the frequency of assigned codes across the repetitions and give first insights into the magnitude of variation of queries, compared to manual coding shown in Figure 1c. The mean number of assigned codes ranges between 11.7 for interview 4 and 16.3 for interview 1, where the standard deviation was observed smallest for interview 5 with 0.82 and highest for interview 3 with 3.09. Compared to manual coding (cf. Figure 1c), it is apparent that the prompt led to a reduced number of codes assigned by the LLM since we explicitly asked for unambiguous assignments with clear relation to the context (cf Table 4). This is a deliberate choice because we discovered during the iterative improvement process of the prompt that sometimes comparatively large numbers (>80) of fragmented codes (single sentence) were assigned by the LLM when not including such restrictions. From the frequencies of the manual coding, we can, for example, derive that no funding proposals were discussed in interviews 1 and 6 and funding is not frequently coded and discussed throughout all interviews. Nevertheless, we can summarize that interviews 1, 3 and 6 were particularly focused on the level of information on legumes in the market, and interview 2 has a focus on both expectations of the dashboard as well as the challenges of implementing the dashboard. Interviews 1 and 2 were more concerned with the data quality and interview 5 did not show many paragraphs that were directly related to the codes. On the other hand, the LLM coded the interviews overall more evenly where only interview 1 showed an increase of the code regarding the level of information detail.
Chain-of-thought-prompt used for LLM supported coding in English and in their original German versions, divided into sections that highlight their intention.
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
Overview of code assignments: (a) frequencies across repetitions of LLM-based coding, (b) mean frequencies and standard deviation of LLM-based coding, (c) manual code frequencies across the code schema, (d) LLM-based code frequencies across the code scheme.
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
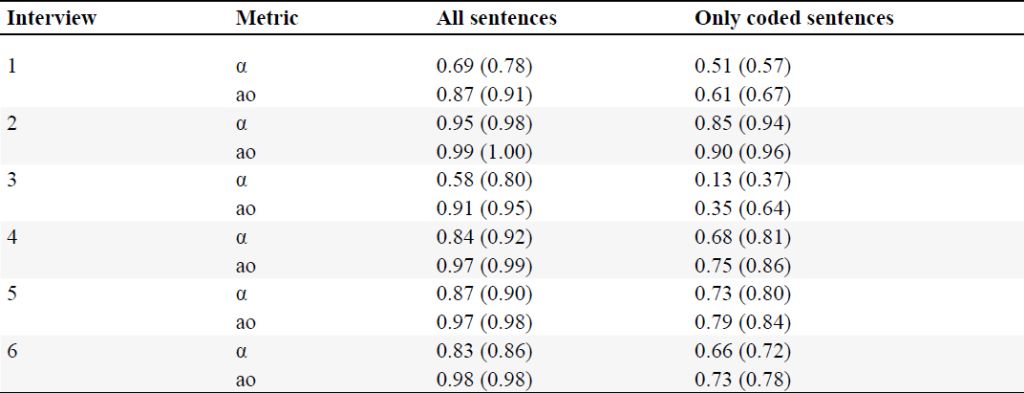
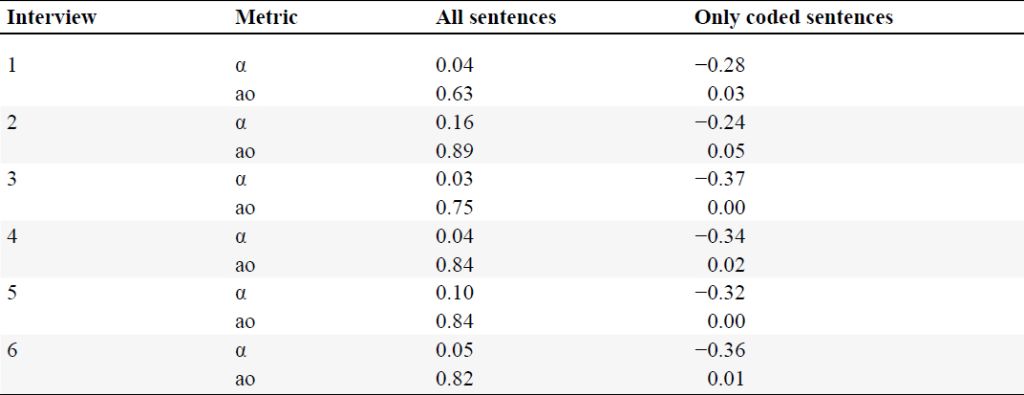
However, code frequencies are one of many indicators and themselves do not reflect whether the code assignment is contextually meaningful. Therefore, we took a closer look at the hot spots of code assignments of the LLM and whether the code assignments between the repetitions differ or are in agreement. Assuming that non-coded sentences were deliberate, we can observe high coding agreement of independent LLM queries, where α ranges from interview 3 with a coefficient of 0.58 to a coefficient of 0.95 of interview 2, shown in Table 5. Consistency in generated codes is important for reproducibility, but also strongly dependent on the underlying model parameters such as temperature or top-k and top-p, which can increase variation, or the token splitting of the embedding and the context length of the model. Yet, setting these parameters too strict might lead to less nuanced responses. By setting temperature to zero, we verify an expected increase in coding agreement (cf. Table 5). We observe that coding is generally sparse, e.g. most sentences are typically not assigned codes in our interviews, and as a result, ao is inflated compared to α. Thus, we further assessed only sentences where at least one repetition is assigned a code. Under these conditions, we observed moderate decreases in α except for interview 3 where the coefficient drastically decreases, indicating that reliability of coding interview 3 is low. Even though the same prompt worked well for most interviews, we can derive that it still remains a balancing act between overfitting and excessive generalization when crafting an appropriate prompt structure. This particular finding highlights a common theme in content analysis where reflexive and iterative code schema development by human intervention may still be required. Hence, hybrid approaches are discussed and recommended in literature, that can retain the iterative nature while scaling to large quantities of text using LLMs (Dunivin, 2025).
Agreement of GPT-4o-based coding of ten independent repetitions based on Krippendorff’s coefficient (α) and the observed agreement (ao).
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
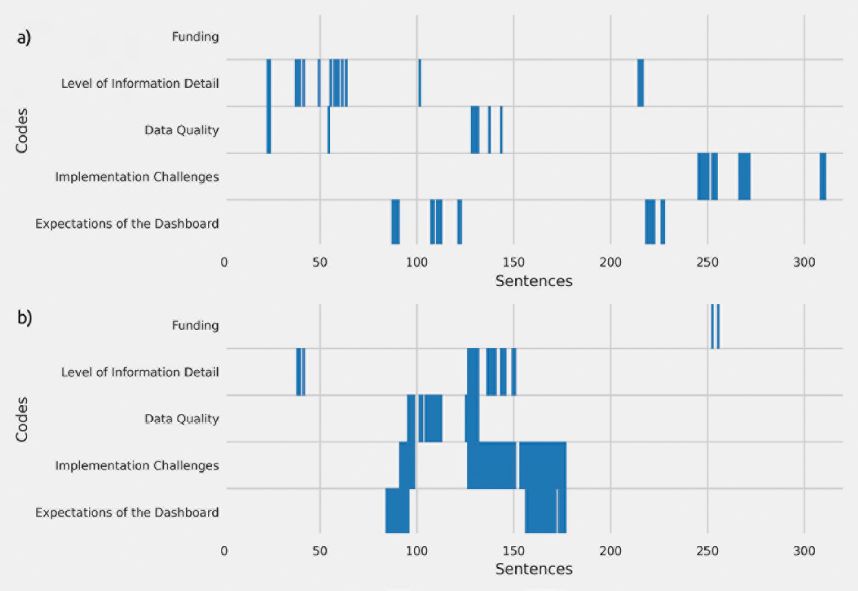
Comparison of LLM and human coder: To investigate why there are substantial differences in coding between the LLM-based and the manual coding, we conducted a case study of interview 1. Interview 1 shows high ao (0.87) within the LLM repetitions across all sentences and a moderate α-coefficient (0.69), which accounts for agreement by chance and uneven coding frequencies. Therefore, when only considering coded sentences, ao (0.61) and the α-coefficient (0.51) are both decreasing, but also more in agreement. On the other side, Table 6 shows the comparison of the consensus of the LLM-based coding and manual coding, where the α-coefficient is close to zero (0.04) and ao is moderate (0.63). This is enforced by Figure 2 which signals that coding between the LLM and manual process still agree on many non-coded sentences, but the actual codes of interest are mostly assigned independent of each other or disagree. However, due to the complexity of the dataset, even manual coding may contain inconsistencies, and thus cannot be considered an entirely flawless reference.
Coded sentences across interview 1 for (a) manual coding and (b) LLM-based coding consensus where at least 50% of the repeated queries are in agreement.
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
Agreement of GPT-4o-based coding, using consensus codes of ten independent repetitions, and manual coding, based on α and the ao.
Citation: International Food and Agribusiness Management Review 28, 3 (2025) ; 10.22434/ifamr.1276
To identify discrepancies between LLM- and manual coding, we examined individual coded sentences from interview 1, evaluating whether they are coherent and provide meaningful insight. For instance, the LLM assigned “funding” to sentences 252 and 255, while the human coder did not. In the context of these code assignments, the interviewer asked for problems that could arise due to the establishment of the dashboard, which is reflected by the human coder who coded these responses as “implementation challenges” (cf. Figure 2). In these sentences, the interviewee noted that price data may be inaccurate because not all trades are included, requiring feedback loops with data sources that could affect future trades. They further emphasized the need for transparency about data sources and limitations. This was not recognized by the LLM (cf. Figure 2), but instead it focused on two sub-clauses that briefly mentioned that the BMEL is currently funding protein plant cultivation (Eiweißpflanzenstrategie) and its relationship to LeguDash. Hence, the LLM reasoned that this is an indirect funding opportunity for LeguDash, missing the context of the surrounding challenges. Whether the human coder overlooked the “funding” aspect is debatable, but it lacks relevance for future funding prospects. It is plausible that this misalignment stems from divergent interpretations of code definitions and on different background information.
Another example of misalignment concerns the “implementation challenges”-code applied to other text passages 90 to 98 and 126 to 176. Particularly, sentences 126 to 133 were coded as “data quality” by the human coder and “level of information detail”, “data quality” as well as “implementation challenges” by the LLM. This occurred following a question regarding information accessibility, to which the interviewee rated legume market data, except for yield related data, as difficult to obtain. The LLM coherently argued and identified both the challenge of data gathering and the inadequacy of data quality, highlighting potential overlaps in code definitions.
Finally, the “expectations of the dashboard”-code exhibited partial agreement in sentences 85 and 95. Before these sentences, the interviewer directly asked for expectations regarding the LeguDash to which the interviewee responded that they expect different sources of data accompanied by simple visualizations and corresponding data sources. However, the LLM failed to capture the subsequent expectations of the interviewee regarding the need for up-to-date data. Conversely, the LLM exclusively identified sentences 156 to 171 as “expectations of the dashboard” in which the interviewee positively discusses the usability of the graphics of the dashboard. The LLM argues that these sentences indirectly describe expectations regarding the possibility to interact with the graphics.
While demonstrating internal reliability within its coding, consistent with recent literature (Dunivin, 2025), we observed limited inter-coder agreement, measured by Krippendorff’s α, when comparing LLM-based coding to human coding of German-language expert interviews concerning funding perspectives of LeguDash. Nevertheless, a fine-grained analysis of individual coding rationales reveals that a substantial proportion of LLM-assigned codes are reasonable and could potentially serve to prime a human coder for more careful analysis, though a subset demonstrate a lack of contextual awareness. This is in accordance with the reflective nature of qualitative content analysis, requiring multiple iteration steps beyond the initial manual code assignments, which can be assisted by an LLM.
5. Limitation
We acknowledge several limitations related to the coding task, divided into challenges concerning the dataset itself and those relating to the technical implementation. The dataset comprises German interviews automatically transcribed, resulting in instances of rare terminology and natural language idiosyncrasies. This can introduce ambiguity, leading to loose contextual connections or grammatically incomplete sentences, which may hinder LLM-based contextual understanding. Another limitation lies in the fact that both the interviews and the manual content analysis were conducted by the same individual, which may have introduced subjective bias or constrained the analytical perspective. The LLM on the other hand is potentially capable of adopting a more neutral perspective.
Furthermore, the technical implementation presented challenges in crafting a general prompt capable of effectively addressing all codes while balancing nuanced responses and minimizing excessive code generation. It remains plausible that the method of sentence enumeration employed also influenced the LLM’s ability to grasp contextual information. Notably, we did not incorporate reasoning for non-coded sentences during initial trials due to difficulties in achieving a functional structured JSON output. However, including such reasoning, even at the cost of increased output length, could prove valuable. Finally, the application of Krippendorff’s α on a per-sentence basis is inherently strict with regard to non-aligned codes, potentially failing to capture the full spectrum of coding justifications and rationales beyond simple agreement.
6. Conclusion
Particularly in niche topics, interviews or languages other than English, are not yet readily evaluable using LLMs, showcasing the limitations of LLMs. Thus, we believe it would be of research interest to further investigate discrepancies and applicability of LLMs on specific tasks such as coding by also comparing performances across languages. Further, since LLMs seemingly require more explicit task definitions, hybrid approaches, e.g. human and LLM interaction, are still essential to fine-tune and investigate prompt performance. For example, during various trial prompts for our analysis, we observed strong fluctuations in regions of focus and the frequency of codes and granularity of codes. Because there is not yet a general solution, fine-tuned LLM models for coding using gold standard datasets or automatic feedback prompts might be worth investigating as well.
Despite limitations, LLM analysis shows promise as a basis for more efficient data analysis, complementing human coders to also reflect about certain sentences and the reasoning behind their coding. This can be particularly helpful in improving coding quality and insights beyond the initial coding phase. Thus, LLMs can reduce manual workload, for example during transcription or initial coding. However, we demonstrated that, while LLM-based coding is reliable, for challenging datasets such as the interviews conducted in this study, LLMs sometimes lack contextual awareness and are not trivially adjusted to perform well for all tasks. Therefore, we recommend researchers to carefully examine automatic coding, especially in the case of zero-shot prompting, and believe more sophisticated methods are required, such as fine-tuned LLMs or automatic feedback workflows.
In addition to analyzing the potential of LLMs, a central focus was on identifying long-term sponsorship and financing options for the LeguDash. The expert interviews made it clear that both public financing and subscription-based models could be potential approaches. Institutions or companies that would be considered as sponsoring institutions preferred flexible and adaptable solutions that would enable easy integration into their existing systems. For this reason, a replica was created at one public institution to meet their requirements. These requirements make it clear that long-term viability of the dashboard depends not only on the choice of financing model, but also on its technical and organizational feasibility.
LeguDash is designed to support legume cultivation by enhancing market transparency and providing reliable market data, thereby aiming to reduce economic uncertainties and improve planning. Although its impact has not yet been formally evaluated, the dashboard is intended to make legume production more attractive to farmers. Legumes contribute to sustainable agriculture through several ecological benefits: they fix atmospheric nitrogen, decrease the reliance on synthetic fertilizers and enhance soil fertility, help prevent soil erosion, and promote biodiversity by enabling more diverse crop rotations and reducing the need for chemical pesticides.
7. Managerial implications
LLM-assisted analysis of qualitative interviews presents a promising avenue for streamlining qualitative research in agribusiness by enabling faster and more efficient processing of complex unstructured data. LLMs can automate labor-intensive tasks such as thematic coding or data organization, allowing agribusinesses to quickly extract actionable insights from extensive qualitative datasets. By identifying recurring themes and relationships in texts, LLMs reduce the time required for manual analysis. However, this does not imply uniform performance across all applications. Our study reveals measurable variations depending on the task and data characteristics, highlighting the importance of context-specific evaluation and careful interpretation of results by some degree of human intervention. At the same time, LLMs offer the potential for a more neutral assessment, which can be meaningfully interpreted and validated by humans when supported with reasoning. Therefore, we believe it remains critical for agribusinesses to pair LLM outputs with expert oversight to ensure context-specific accuracy and to mitigate potential biases inherent in automated analysis, in particular when working with heterogeneous datasets such as interviews.
Companies interested in hosting the LeguDash dashboard can adopt flexible financing models that align with their specific operational contexts while ensuring accessibility for a broader user base. A hybrid financial structure, balancing public access with optional subscription-based features can enhance financial sustainability and system usability. Modular customization is a key aspect. By allowing users to tailor the dashboard’s functionalities to their specific needs, the platform can increase relevance and user engagement.
Integration into existing corporate systems should be seamless, minimizing technical hurdles and ensuring user adoption. To achieve this, providing API connections or replica capabilities, where the dashboard mirrors existing company systems, may significantly enhance compatibility and ease of implementation. Offering scalable solutions, such as modular reporting tools or customized visualization options, enables companies to adopt the platform incrementally. Regular monitoring, updates, and user feedback loops are crucial for maintaining the system’s reliability and relevance. A dedicated team for maintenance and user support will ensure that the platform adapts to market and user needs over time. Incorporating advanced analytical tools, such as predictive modeling and trend analysis, could further enhance the dashboard’s value for users, offering actionable insights.
With regard to financing the dashboard, public funding models present an opportunity to position LeguDash as a public good that enhances market transparency. However, securing such funding requires engaging policymakers and demonstrating the broader socio-economic benefits of transparency in the legume market. Subscription-based models could appeal to private stakeholders willing to invest in market intelligence. For example, tiered pricing structures or pay-per-use features can cater to users with varying levels of demand. While partnerships with industry associations and companies are considered viable financing options, the neutrality of such stakeholders is important. To ensure the objectivity and reliability, the development of LeguDash was supported by a state-affiliated institution, which is bound by a strict commitment to neutrality. This partnership ensures that the dashboard remains unbiased and its data remains independent, even if industry stakeholders are involved in the financial model. Data-as-a-service models may also prove viable. Companies or farms providing data to the platform could receive free or discounted access, fostering a symbiotic relationship. This approach incentivizes continuous data sharing, enriching the dashboard’s utility and reliability. Lastly, fostering partnerships with industry associations, NGOs, and academic institutions can create synergies that reduce development and operational costs while expanding the dashboard’s reach and credibility. The ultimate goal should be to create a dynamic, user-centric system that evolves alongside market demands, ensuring long-term sustainability and adoption.
Acknowledgements
Different AI-tools were used in the literature review and to assist in the writing and text editing process. This study was funded within the LeguNet project, which is part of the protein plant strategy (Eiweißpflanzenstrategie) of the Federal Ministry of Food and Agriculture of Germany (BMEL). This article is funded by the Open Access Publication Fund of South Westphalia University of Applied Sciences. The authors would like to thank all interview partners as well as all persons, institutions and organizations supporting the recruitment. The authors declare no financial conflicts of interest. However, they acknowledge that LeguDash was developed within the LeguNet project, in which the authors are actively involved as publicly financed researchers. Given this connection, the authors have a professional and strategic interest in the continued functioning, development, and long-term viability of LeguDash. This interest is rooted in the broader goal of supporting market transparency and promoting legume cultivation through evidence-based tools.
References
Ashwin, J., A. Chhabra and V. Rao. 2023. Using large language models for qualitative analysis can introduce serious bias. arXiv: 2309.17147.
Chew, R., J. Bollenbacher, M. Wenger, J. Speer and A. Kim. 2023. LLM-assisted content analysis: Using large language models to support deductive coding. arXiv: 2306.14924.
De Paoli, S. 2024. Performing an inductive thematic analysis of semi-structured interviews with a large language model: An exploration provocation on the limits of the approach. Social Science Computer Review 42 (4): 997–1019.
Dunivin, Z.O. 2025. Scaling hermeneutics: a guide to qualitative coding with LLMs for reflexive content analysis. In EPJ Data Science 14(1): 28. https://doi.org/10.1140/epjds/s13688-025-00548-8
Hayes, A.S. 2025. “Conversing” with qualitative data: enhancing qualitative research through large language models (LLMs). International Journal of Qualitative Methods 24: 16094069251322346.
Jensen, E.S., M.B. Peoples, R.M. Boddey, P.M. Gresshoff, H. Hauggaard-Nielsen, B.J.R. Alves and M.J. Morrison. 2012. Legumes for mitigation of climate change and the provision of feedstock for biofuels and biorefineries. A review. Agricultural Systems 108: 23–35. https://doi.org/10.1007/s13593-011-0056-7
Kim, K., Y. Ryoo, S. Zdravkovic and S. Yoon. 2024. Price transparency in international retailing on digital platforms, International Marketing Review 41(5): 1133–1160.
Kizito, A.M. 2019. The structure, conduct, and performance of agricultural information systems in sub-Saharan Africa. Gates Open Research 3: 858: https://doi.org/10.21955/gatesopenres.1115782.1
Klievink, B., N. Bharosa and Y.H. Tan. 2016. The collaborative realization of public values and business goals: governance and infrastructure of public-private information platforms. Government Information Quarterly 33(1): 67–79.
Klug, L. and W. Prinz. 2023. Fair prices for sustainability in agriculture and food. Requirements and design options for a data-based transparency system. In Proceedings of the 24th Annual International Conference on Digital Government Research (DGO 2023). Association for Computing Machinery, New York, NY, pp. 124–133. https://doi.org/10.1145/3598469.3598525
Knezevic, S. Z. and D. R. Shaw. 2021. Legumes in sustainable agriculture: their role and potential. Agronomy Journal 113(3): 778–790.
Kshetri, N. 2018. Blockchain’s roles in meeting key supply chain management objectives. International Journal of Information Management 39: 80–89. https://doi.org/10.1016/j.ijinfomgt.2017.12.005
Köpp, D., H. Bertram, B. Kezeya, P. Zerhusen-Blecher, T. Schäfer, M. Gültas and M. Mergenthaler. 2024. LeguDash - A prototype of a dashboard for more transparency in the legume market. 44th GIL - Annual Conference, Biodiversity through digital agriculture. dl.gi.de/sver/api/core/bitstreams/3a79e6e8-9e1b-419f-86ca-1084e3ddf6e8/content
Köpp, D. and H. Bertram, H. 2025. Identifizierung von Finanzierungs- und Trägerschaftsmodellen für das LeguDash-Dashboard durch eine LLM-gestützte Analyse qualitativer Experteninterviews. In: Gesellschaft für Informatik e.V. (Hrsg.), Digitale Infrastrukturen für eine nachhaltige Land-, Forst- und Ernährungswirtschaft. 45. GIL-Jahrestagung, 17.–18. Februar 2025, Freising. Gesellschaft für Informatik, Bonn, pp. 181–184. https://doi.org/10.18420/giljt2025_30
Löhr, B. 1977. Bewertung von Futtermitteln nach ihrem Energie- und Nährstoffgehalt sowie ihren Marktpreisen, Übersichten zur Tierernährung, 5(1), 55–72.
Luo, F., W. Mi and W. Liu. 2024. Legume–grass mixtures improve biological nitrogen fixation and nitrogen transfer by promoting nodulation and altering root conformation in different ecological regions of the Qinghai–Tibet Plateau. Frontiers in Plant Science 15: 1375166. https://doi.org/10.3389/fpls.2024.1375166
Mardenli, A., D. Sackmann and S. Rhein. 2023. Current challenges in agricultural supply chains: An empirical assessment based on expert perspectives. Transportation Research Procedia 73: 66–76. https://doi.org/10.1016/j.trpro.2023.11.893
Overgaard, J., P. Baltzer and H. Peter-Møllgaard. 2008. Information exchange, market transparency and dynamic oligopoly. University of Aarhus Economics Working Paper No. 2007-3. http://dx.doi.org/10.2139/ssrn.1141749
Poeplau, C., A. Don and A. Oschlies. 2011. Soil carbon sequestration and land use change: a meta-analysis. Global Change Biology 17(7): 2184–2196. https://doi.org/10.1111/j.1365-2486.2010.02316.x
Singh, N. and K.A. Dey. 2023. A typology of agricultural market information systems and its dimensions: case studies of digital platforms. Electronic Markets 33: 42. https://doi.org/10.1007/s12525-023-00665-0
Smadja, T. and F. Muel. 2021. Analysis of the EU legume value chains from the H2020 LegValue project: what insights for organic value chains? Available online at https://www.ocl-journal.org/articles/ocl/full_html/2021/01/ocl210005s/ocl210005s.html
Stagnari, F. 2017. Legumes in crop rotations: benefits and challenges. Field Crops Research 202: 64–75. https://doi.org/10.1016/j.fcr.2017.06.003
Tollens, E. 2006. Market information systems in sub-Saharan Africa: challenges and opportunities. Catholic University of Leuven, Leuven.
Rasheed, Z., M. Waseem, A. Ahmad, K.K. Kemell, W. Xiaofeng, A.N. Duc and P. Abrahamsson. 2024. Can large language models serve as data analysts? a multi-agent assisted approach for qualitative data analsis. arXiv: 2402.01386.
Corresponding author:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}